(* represents the equal contribution)
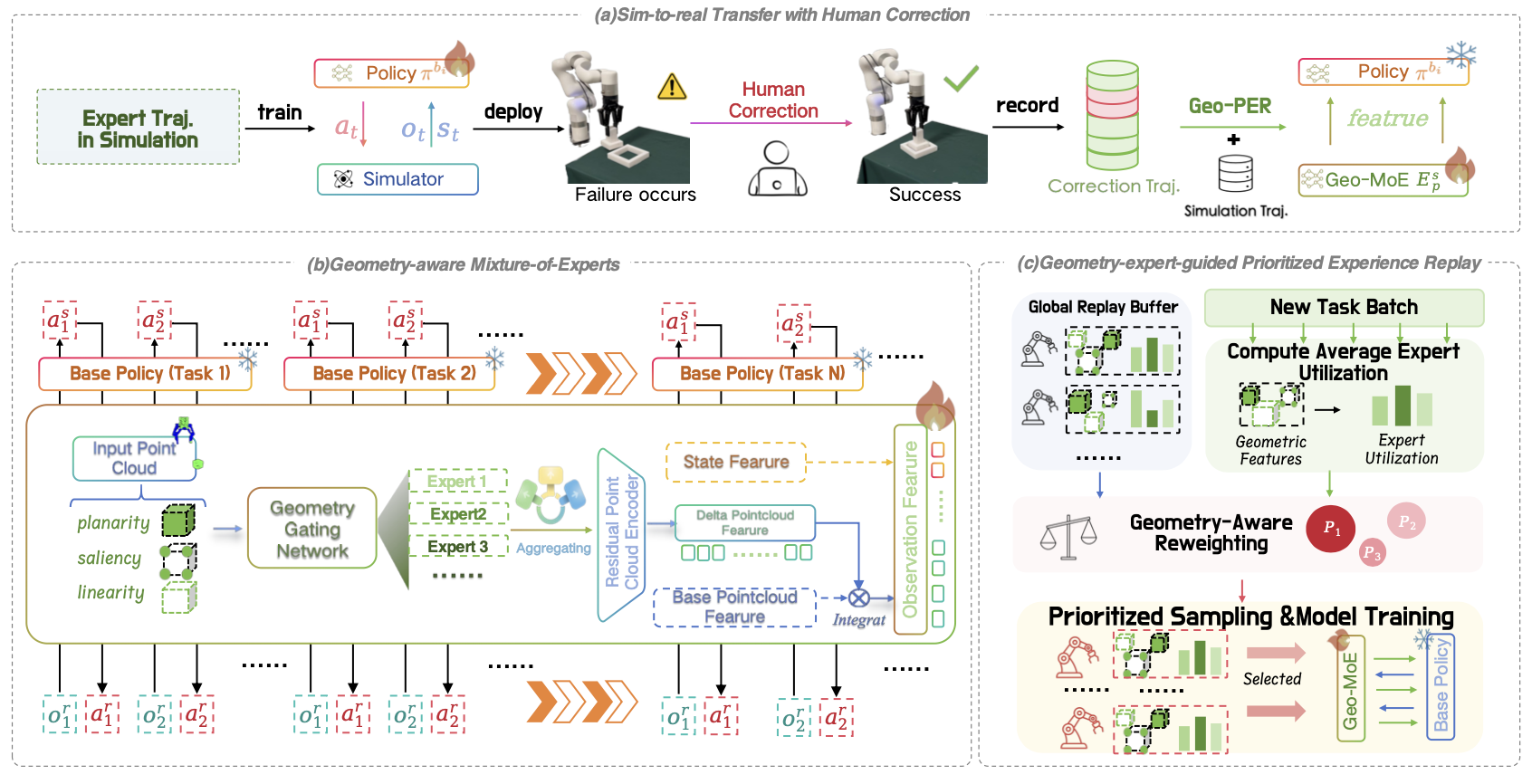
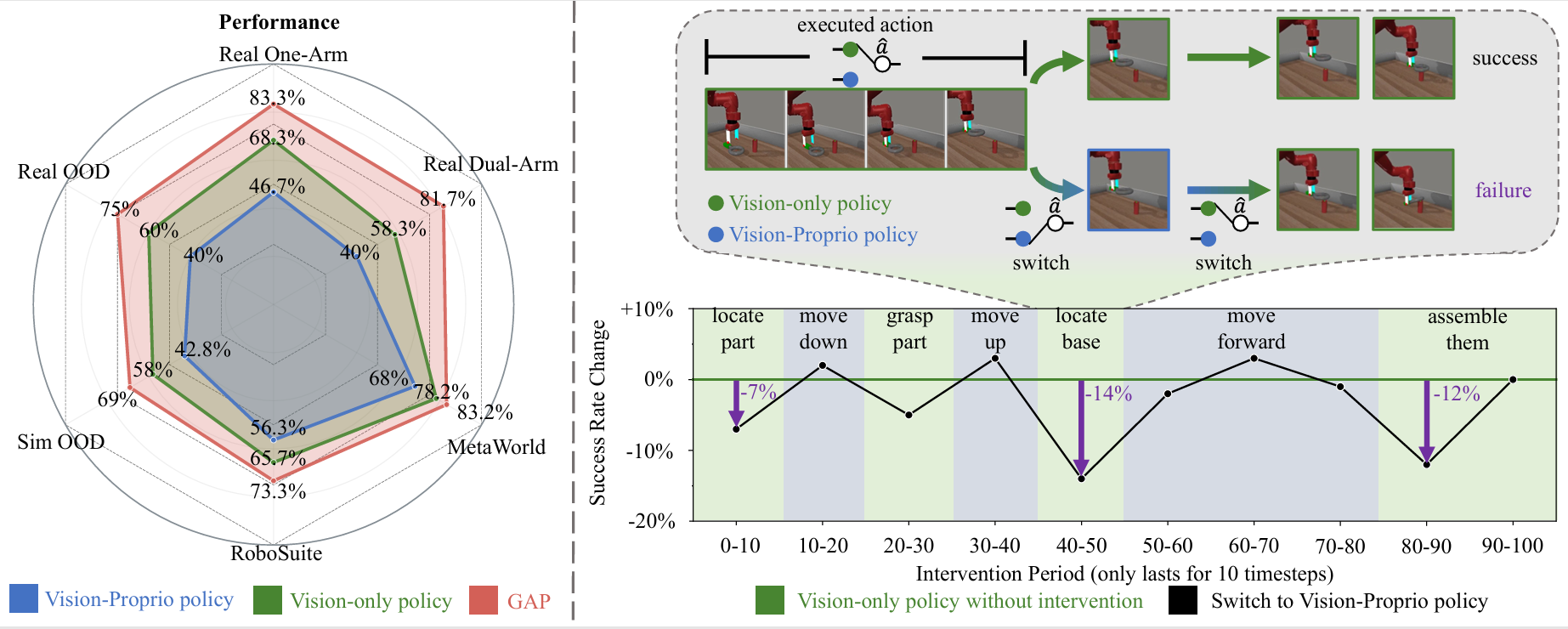
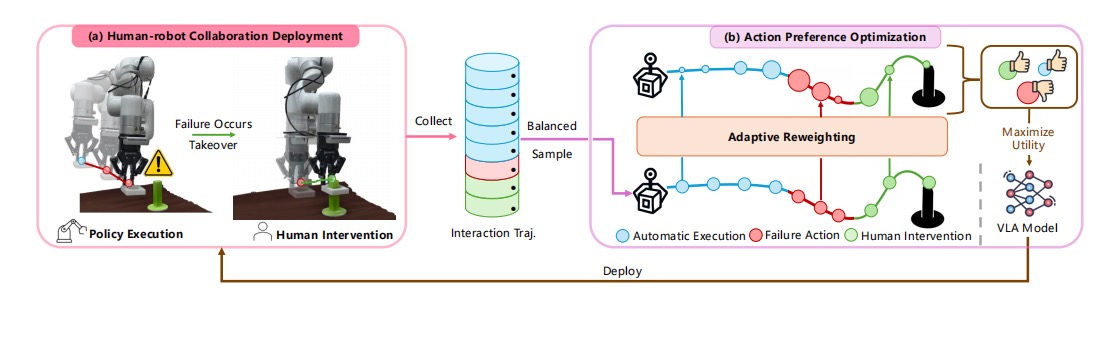
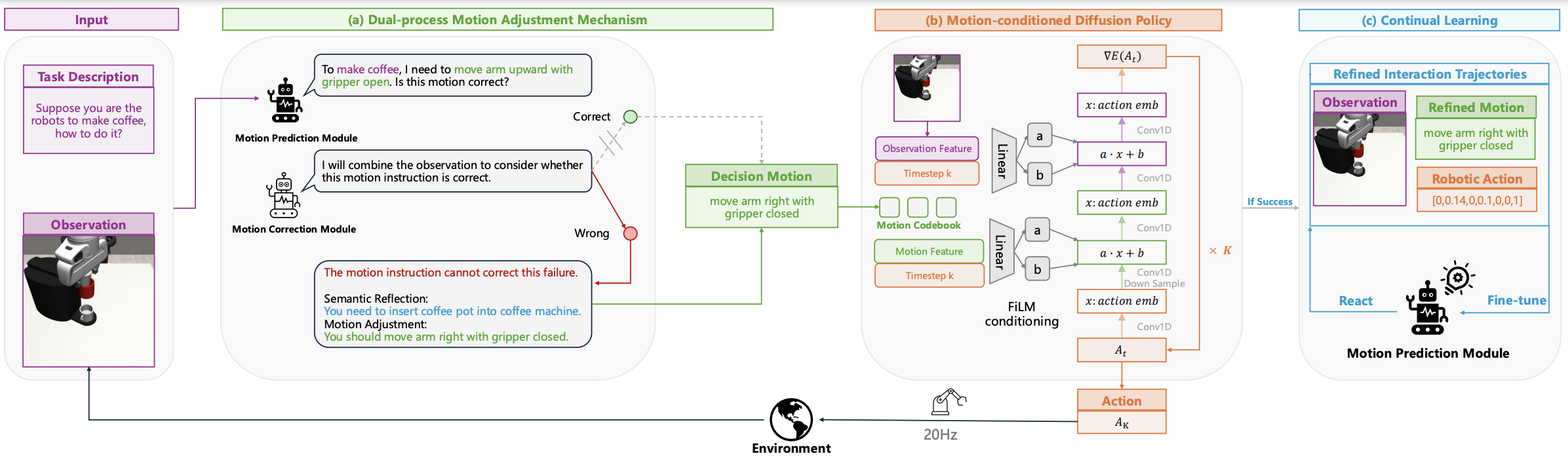
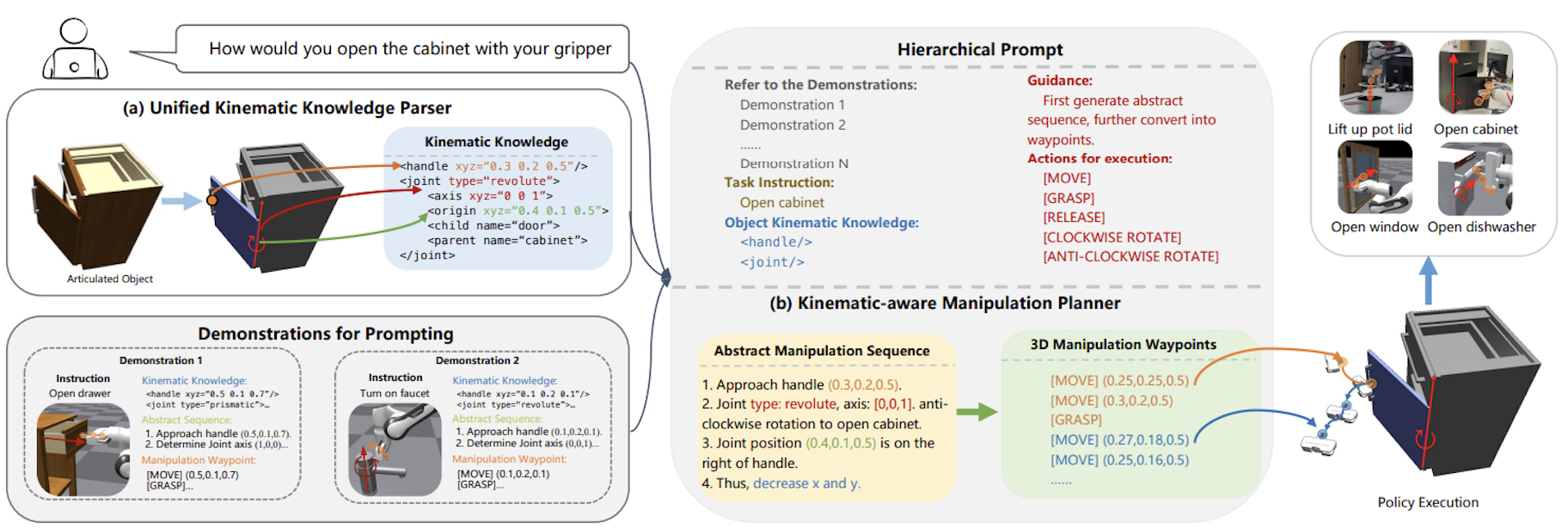
GeCo-SRT: Geometry-aware Continual Adaptation for Robotic Cross-Task Sim-to-Real Transfer
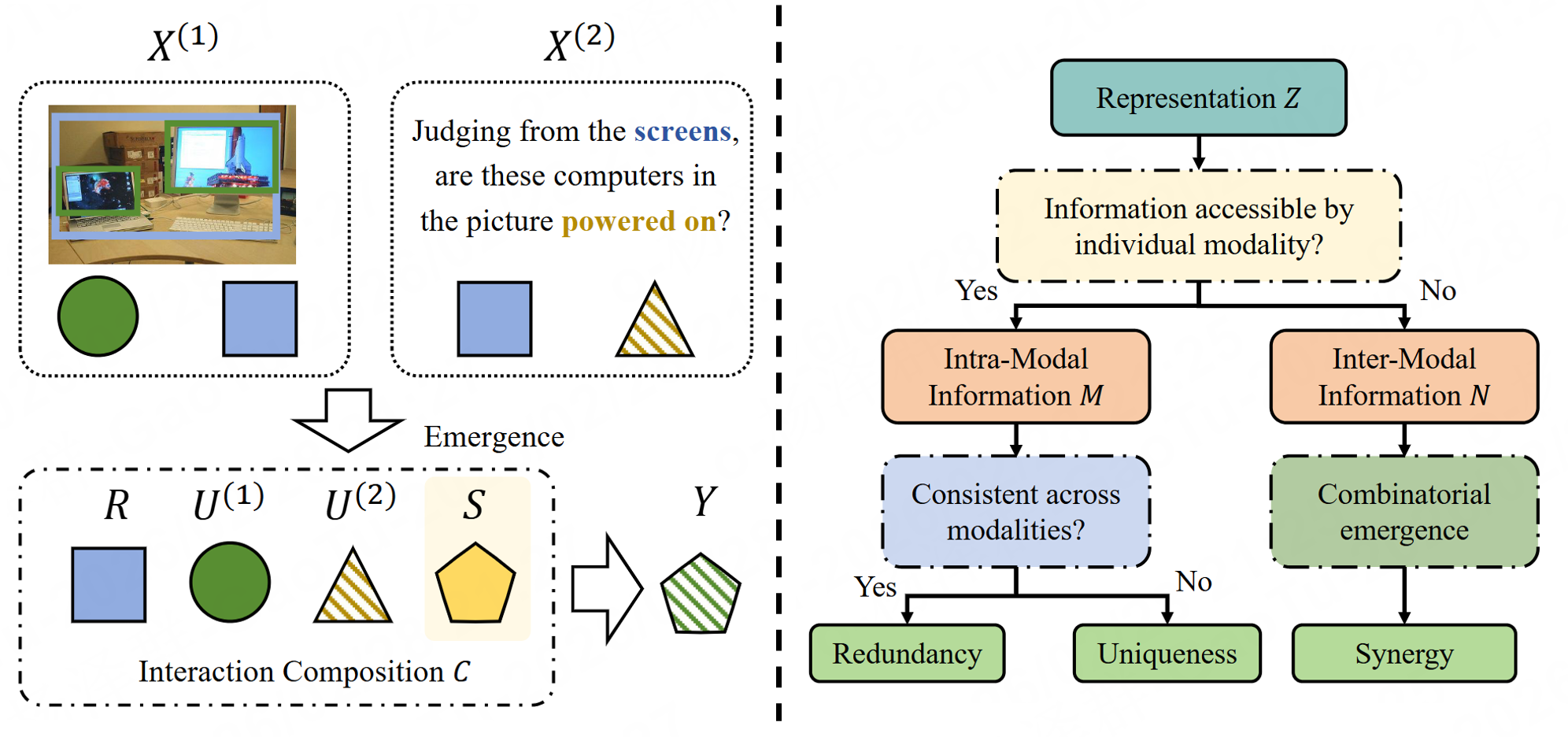
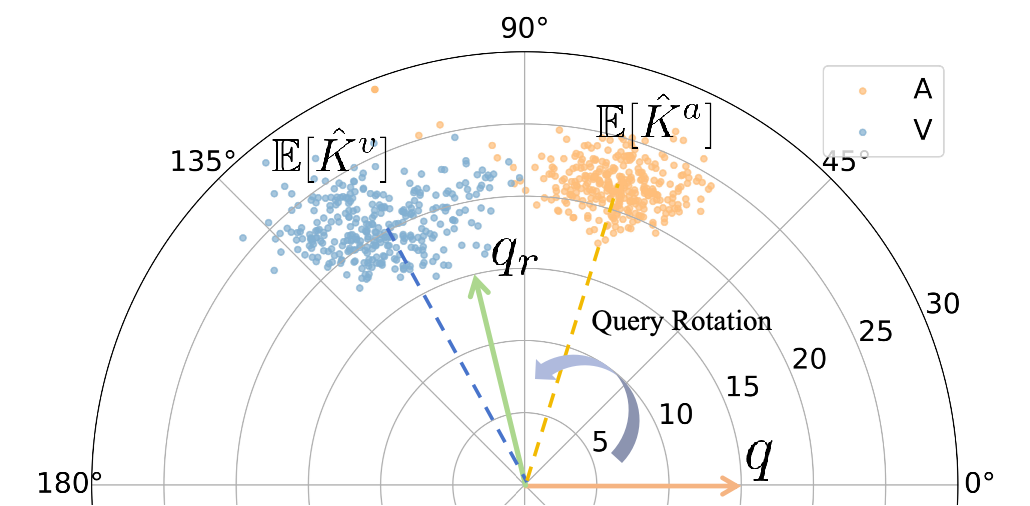
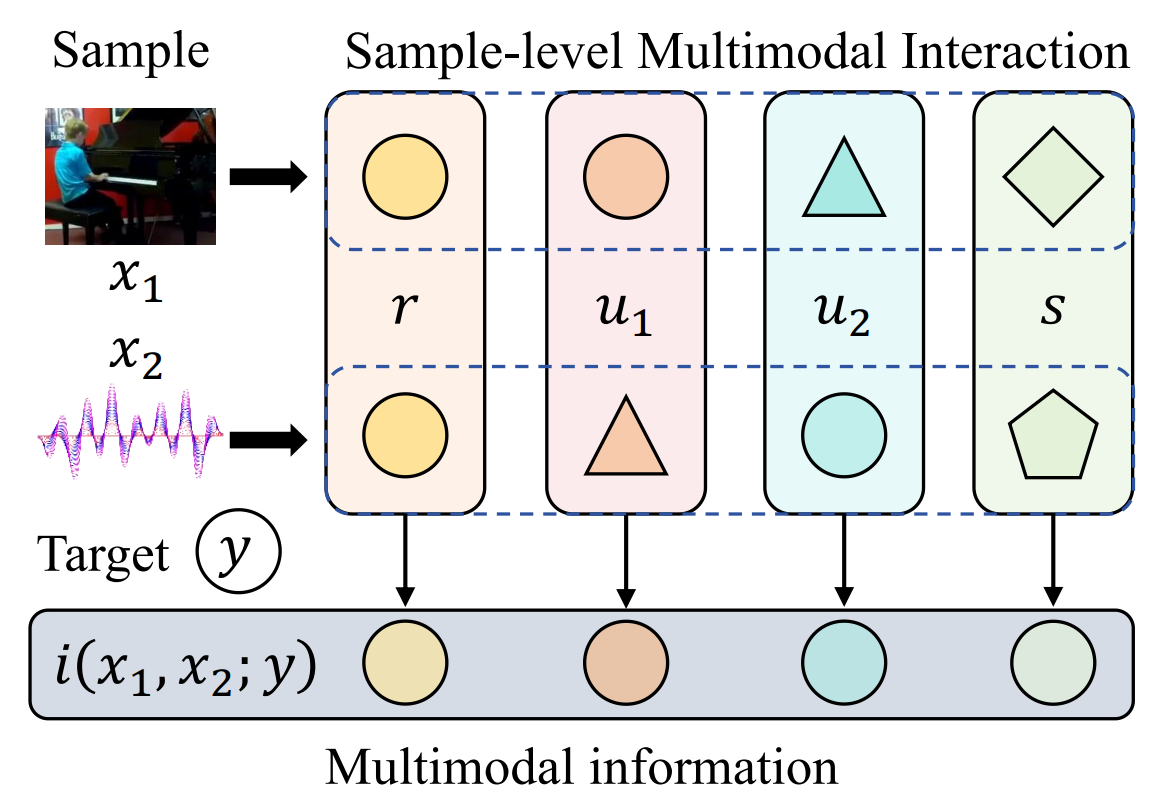
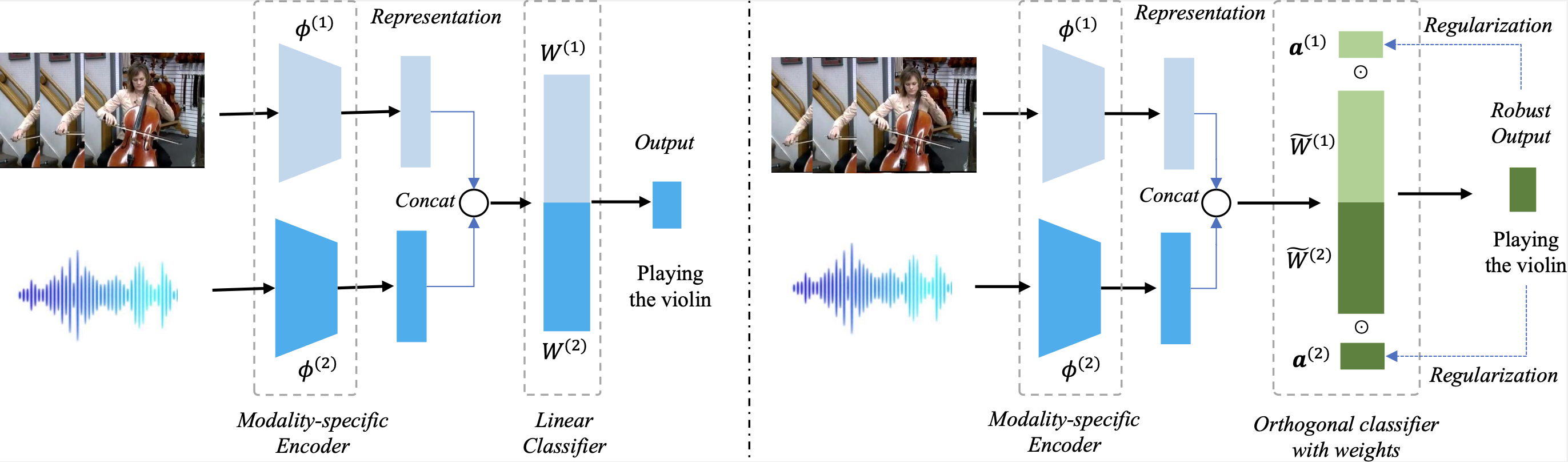
Information-Theoretic Decomposition for Multimodal Interaction Learning
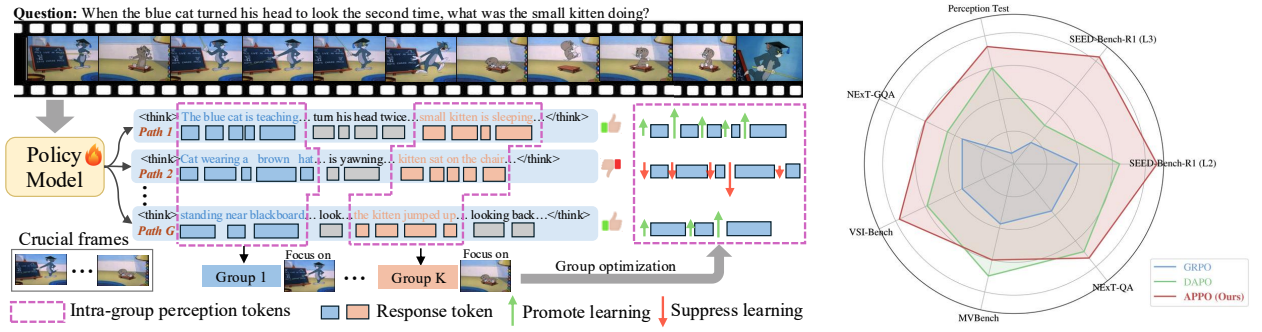
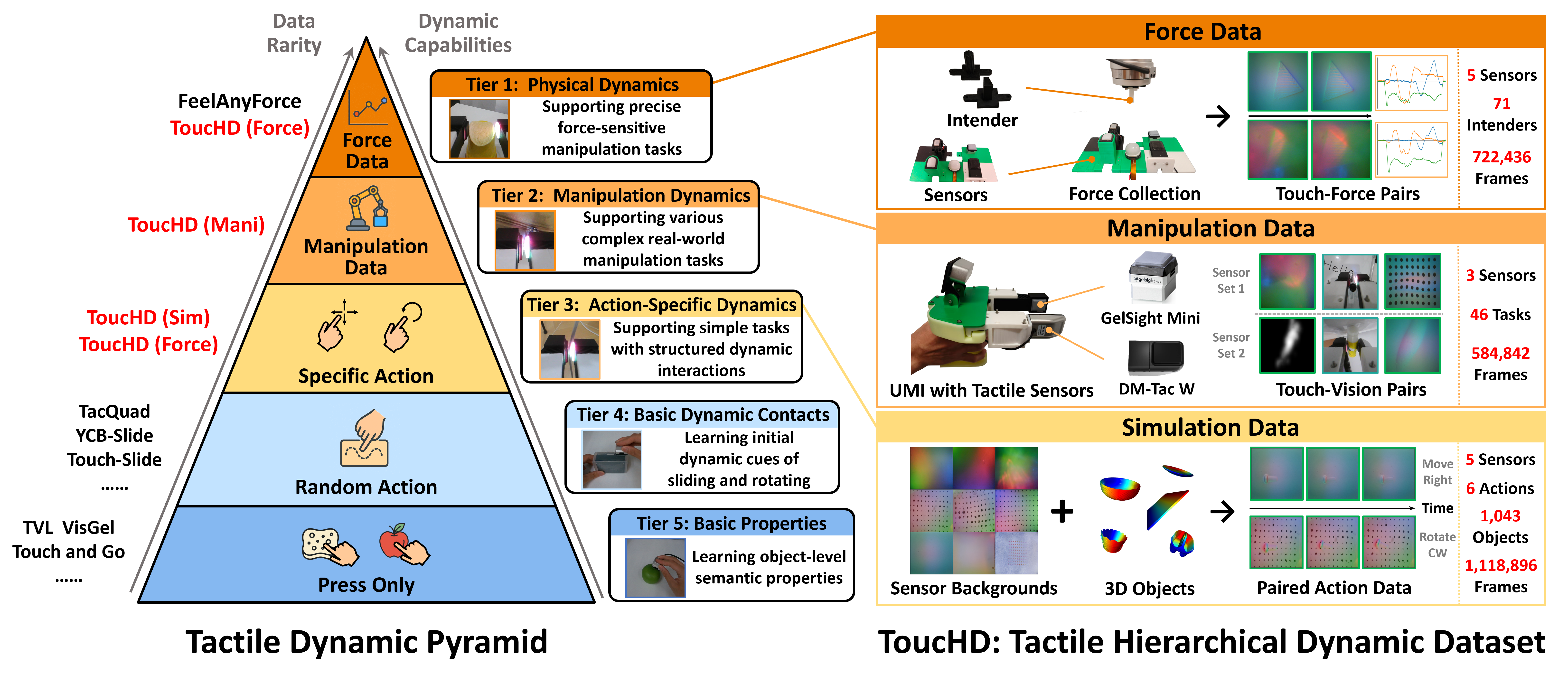
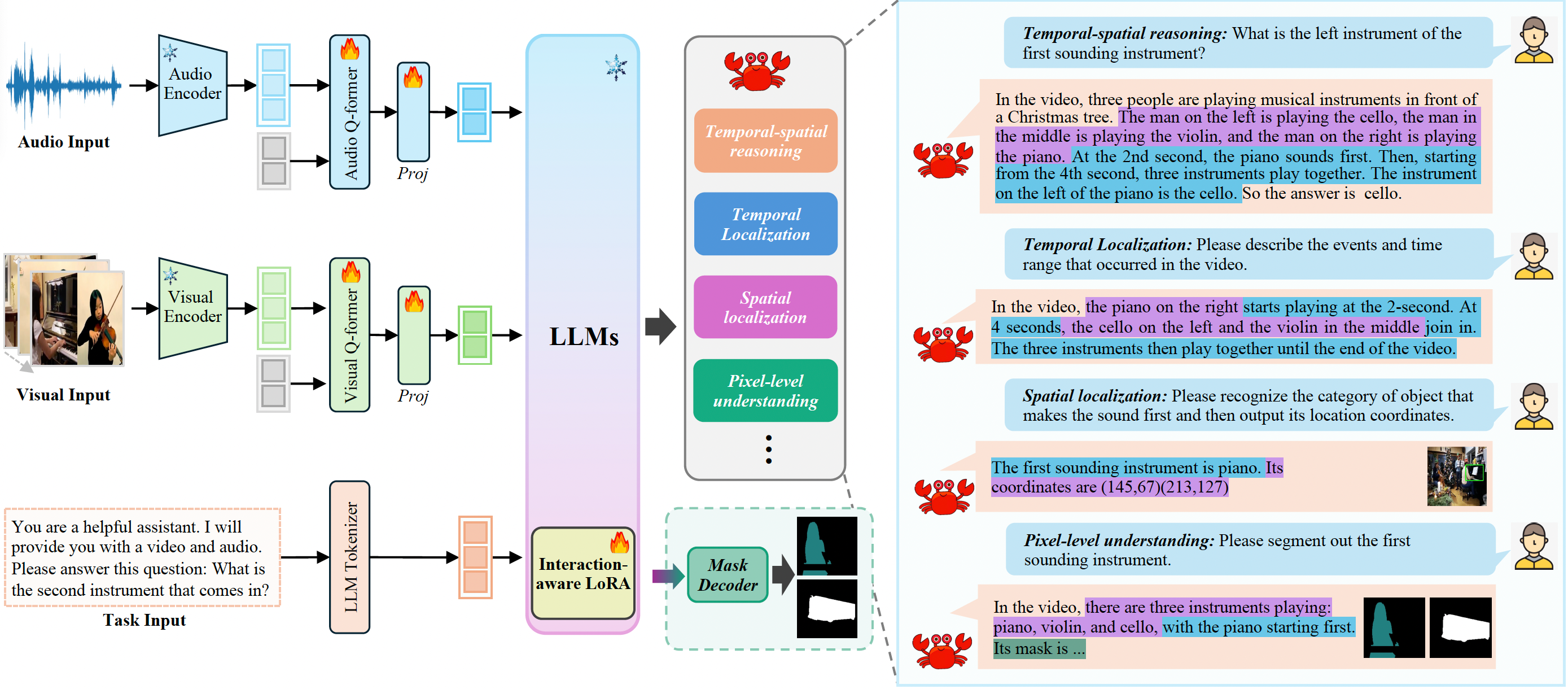
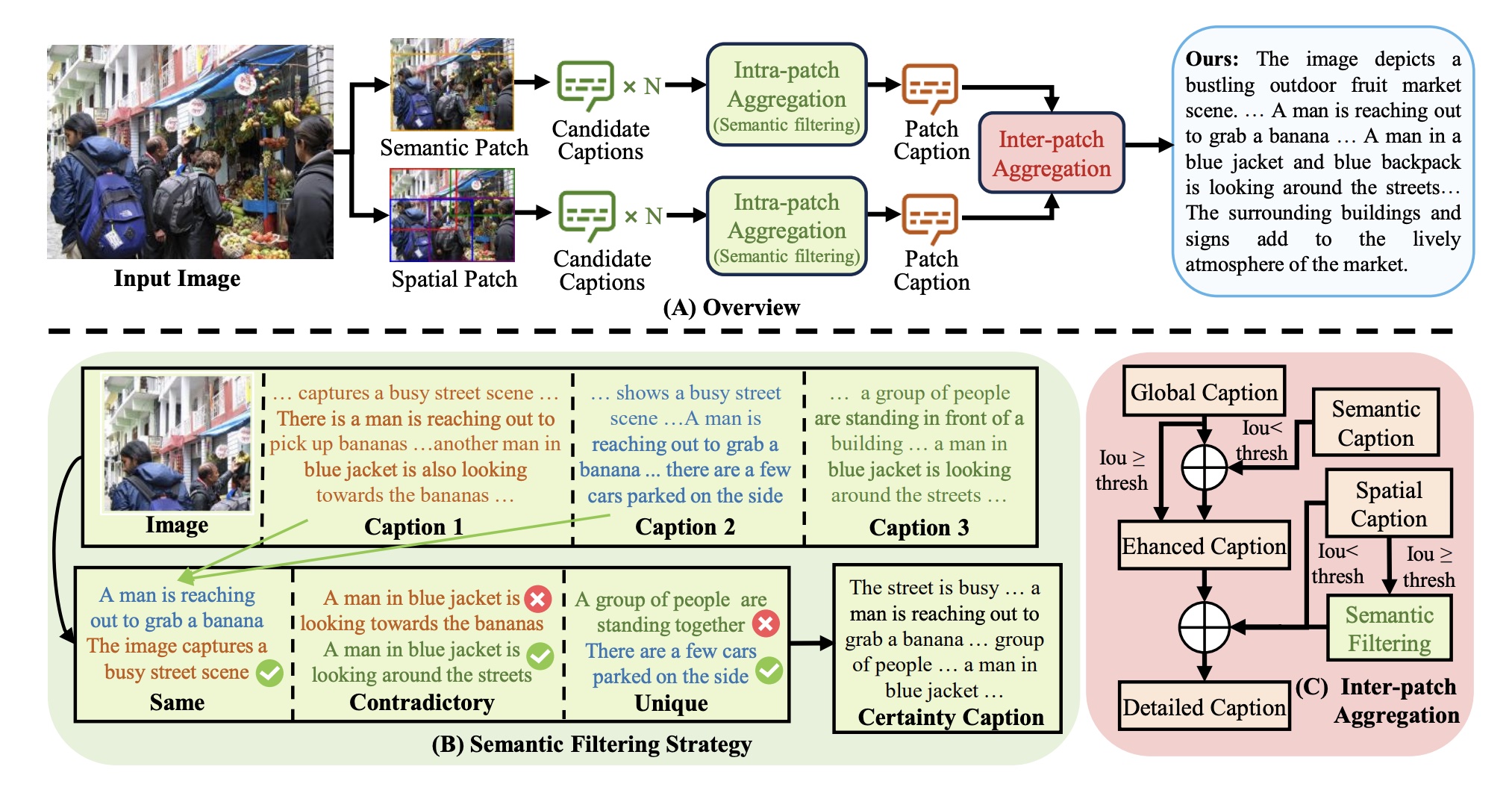

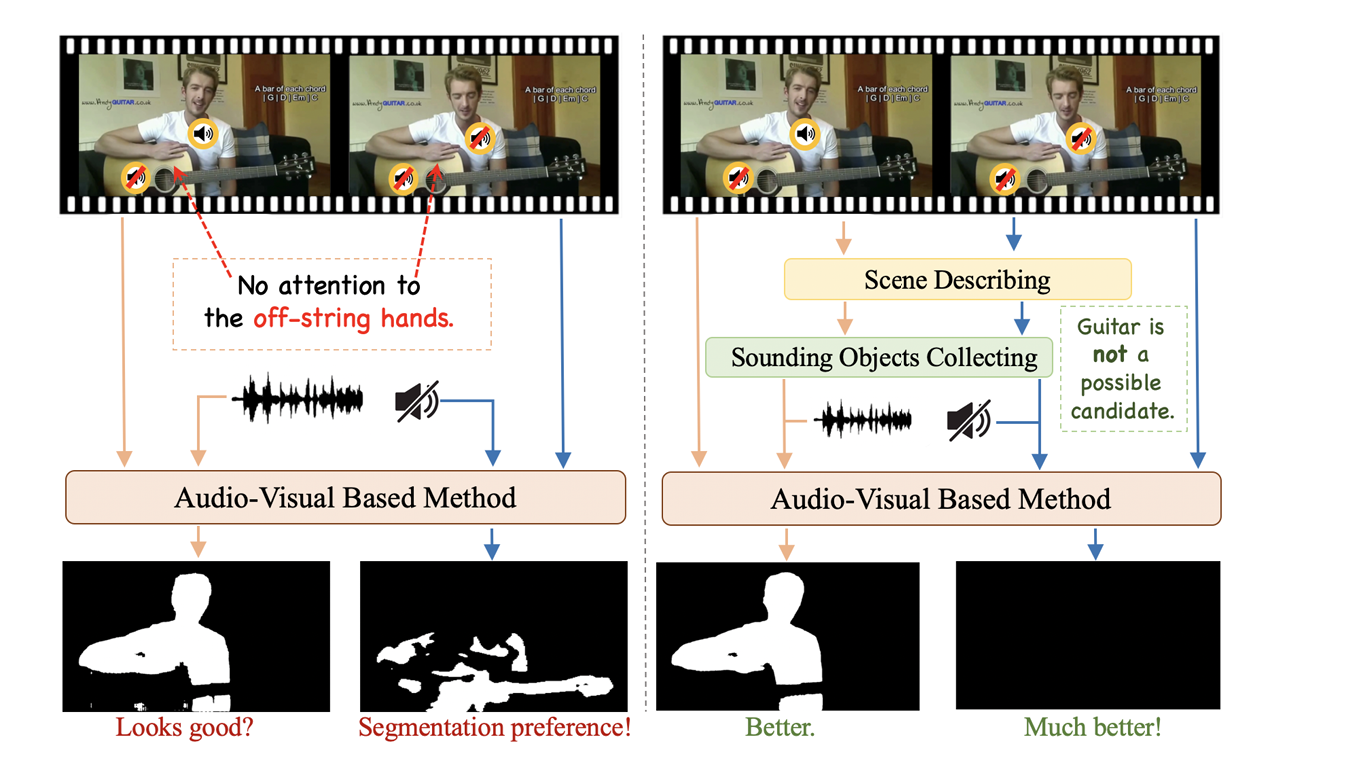
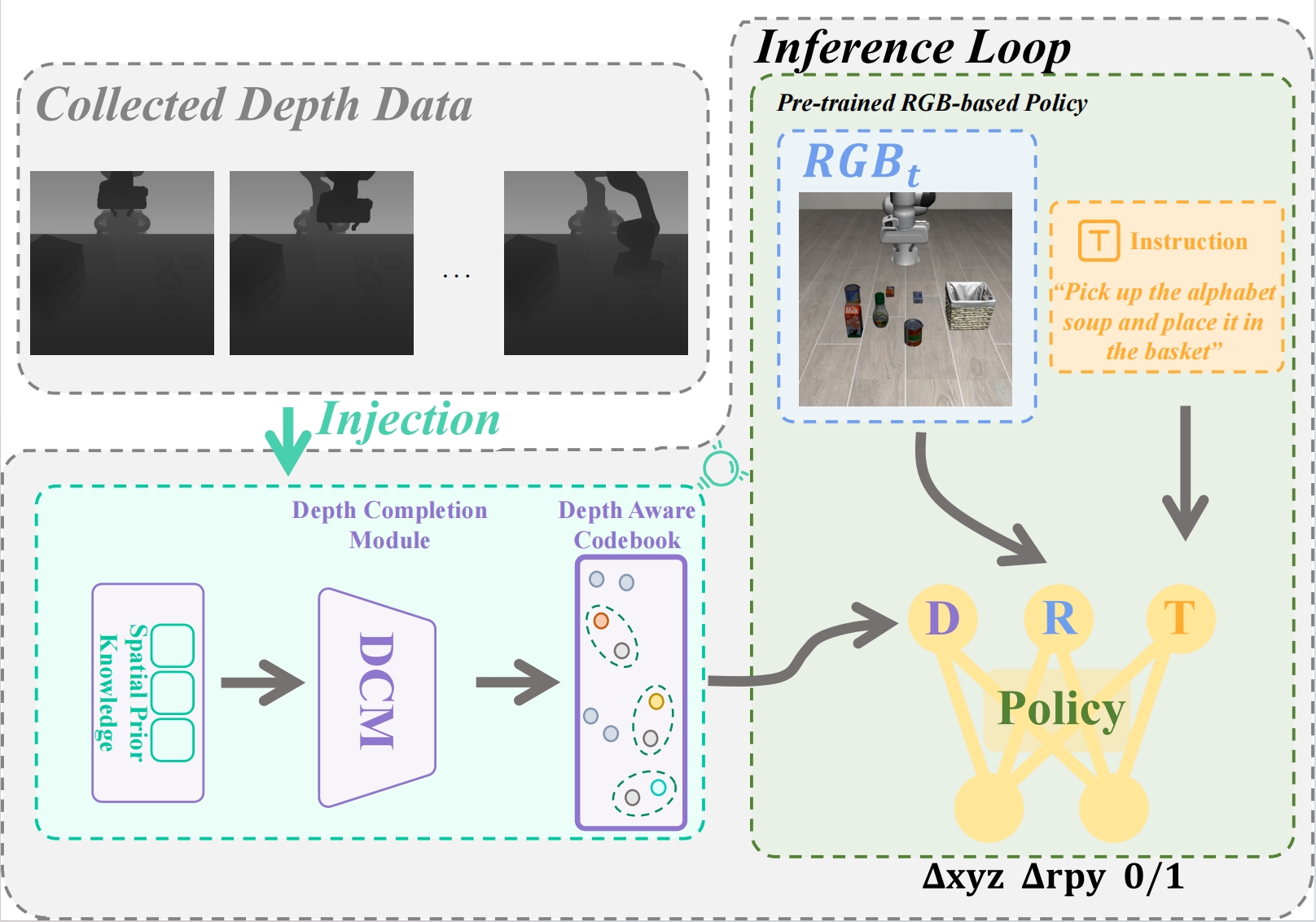
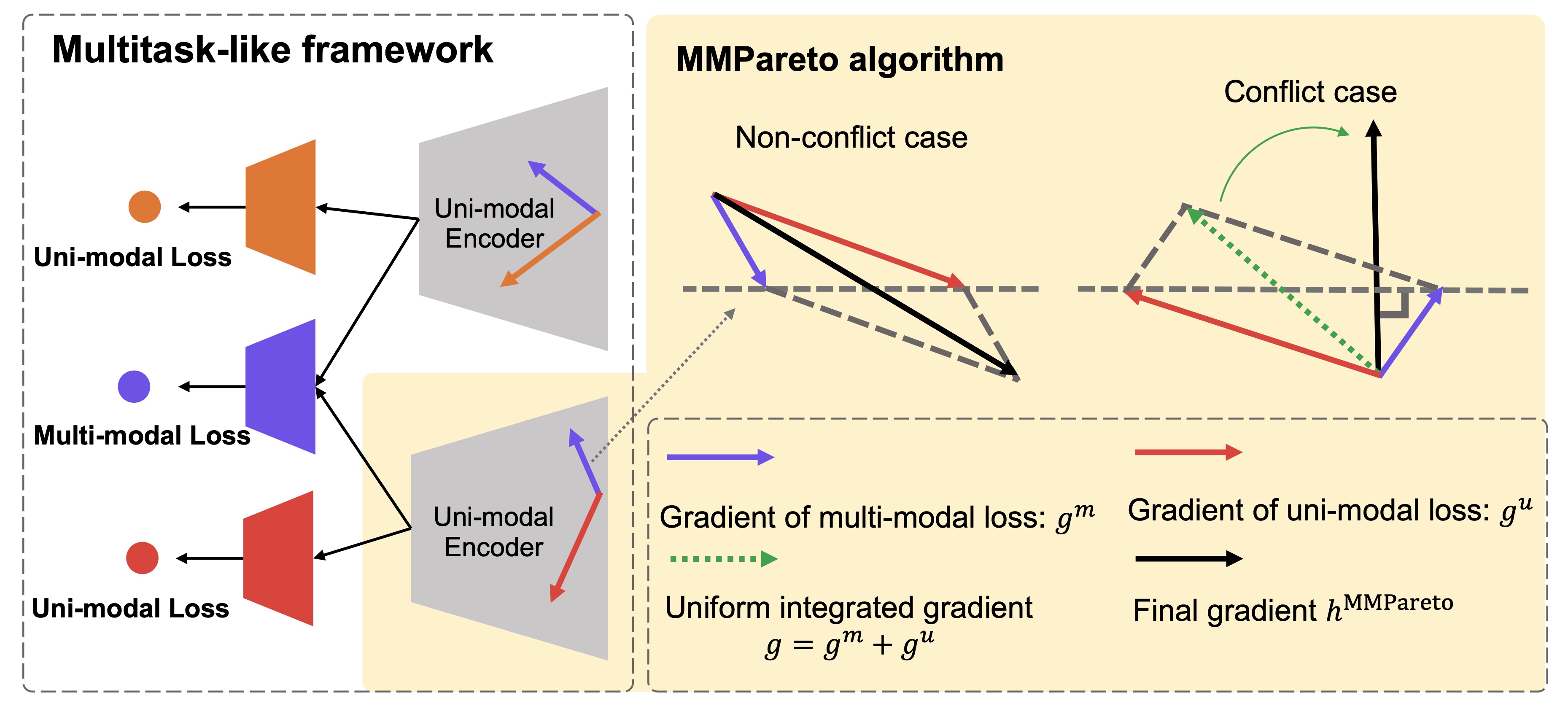
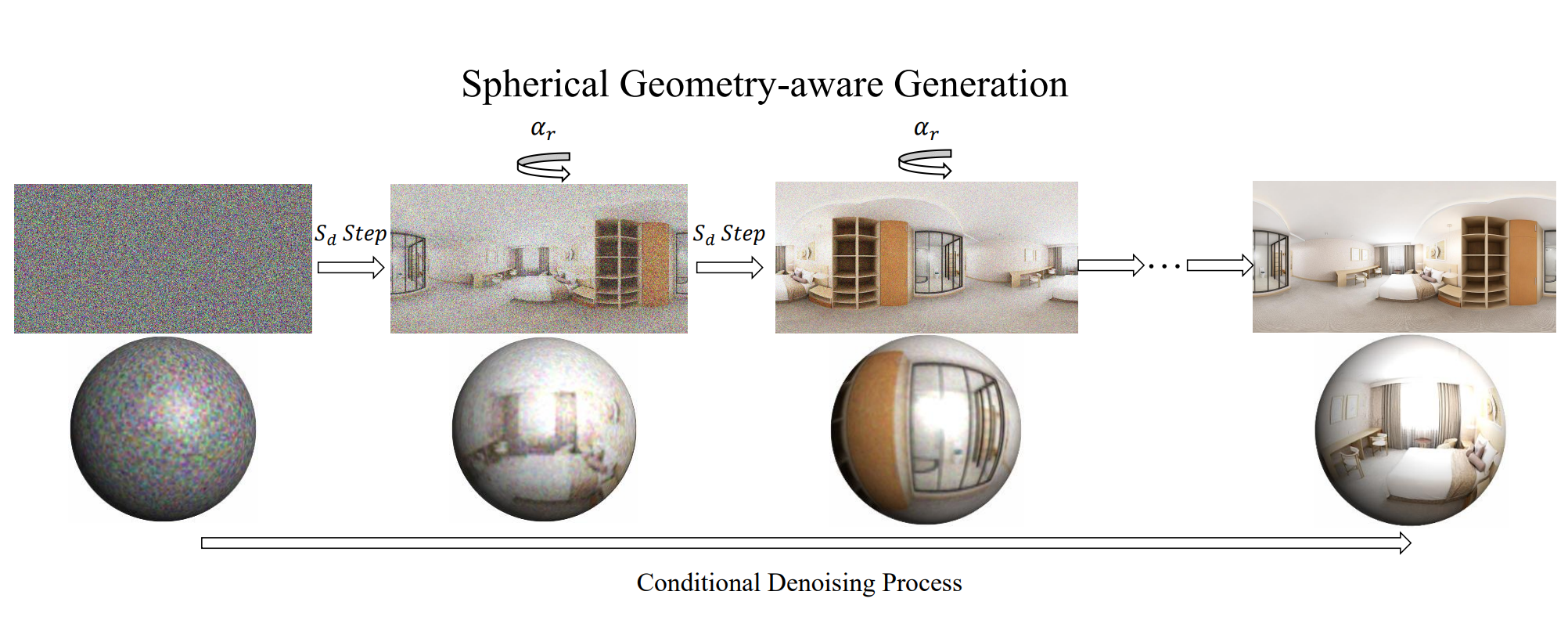
SphereDiffusion: Spherical Geometry-aware Distortion Resilient Diffusion Model

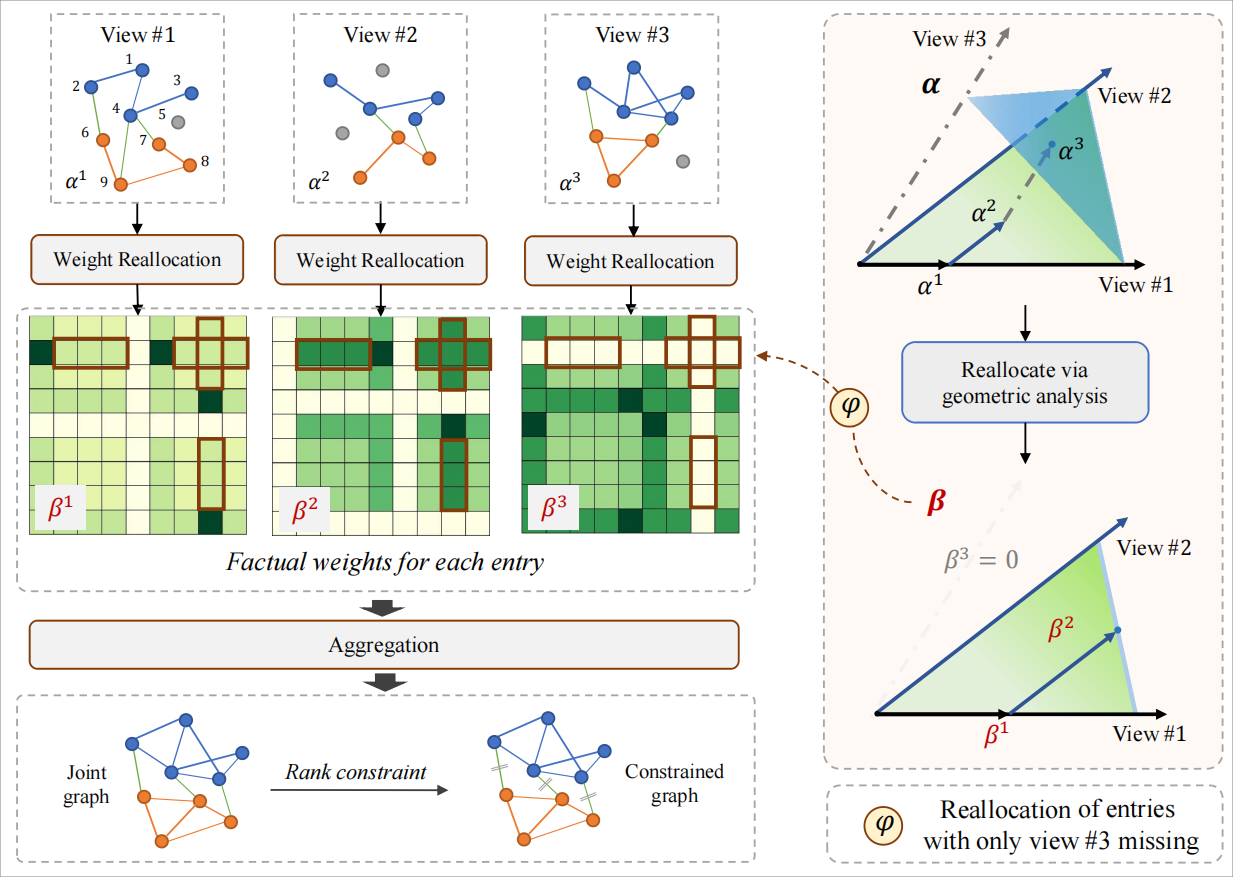

TikTalk: A Video-Based Dialogue Dataset for Multi-Modal Chitchat in Real World

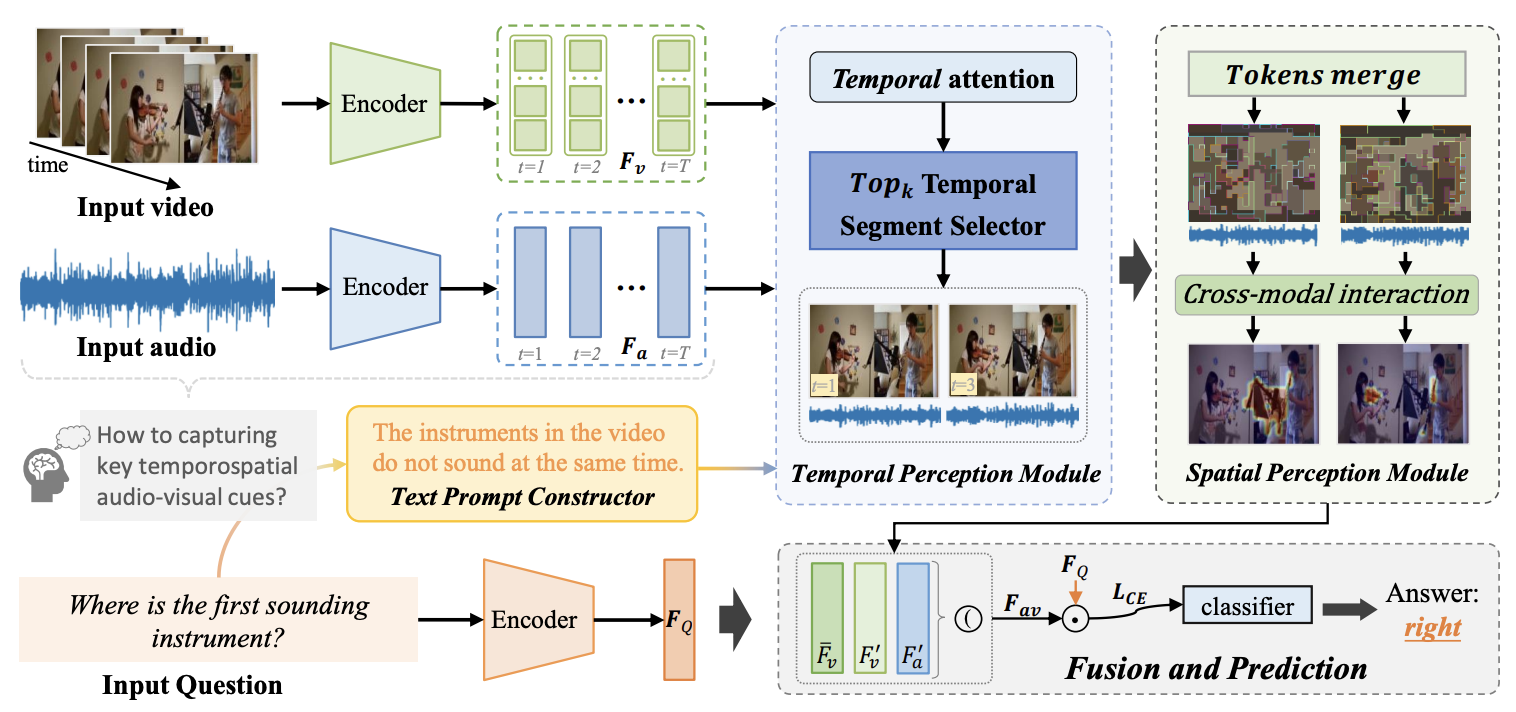
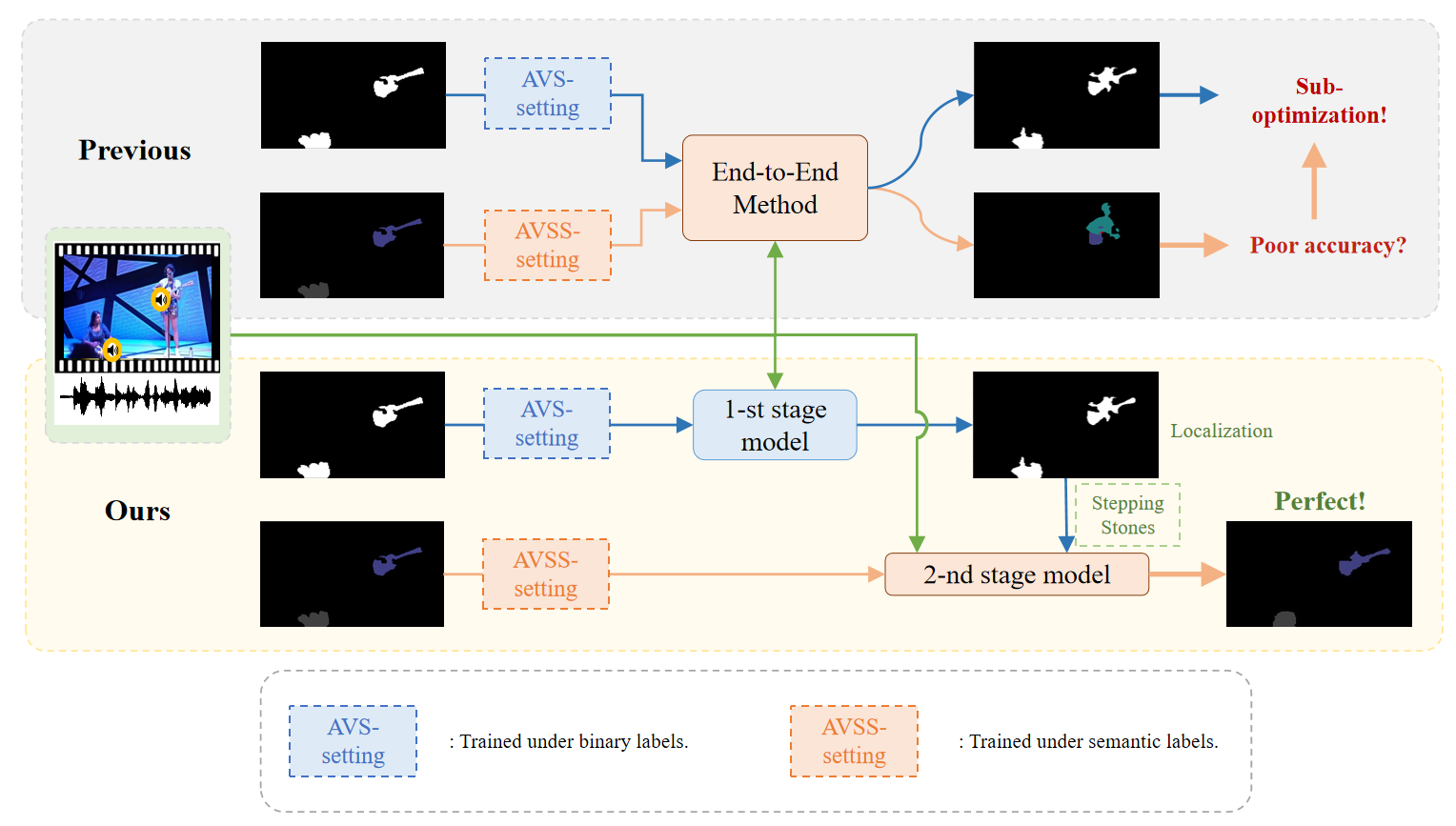
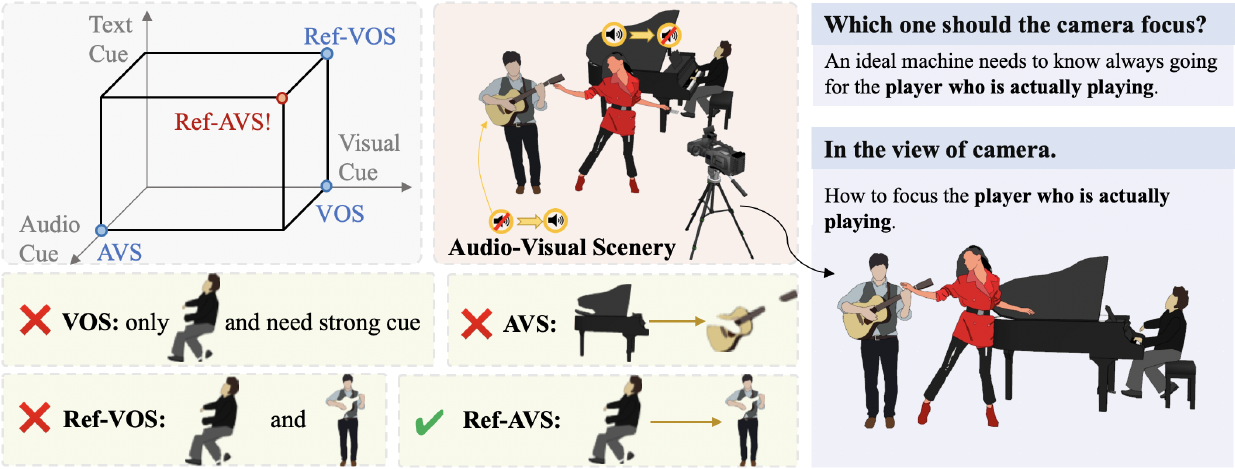
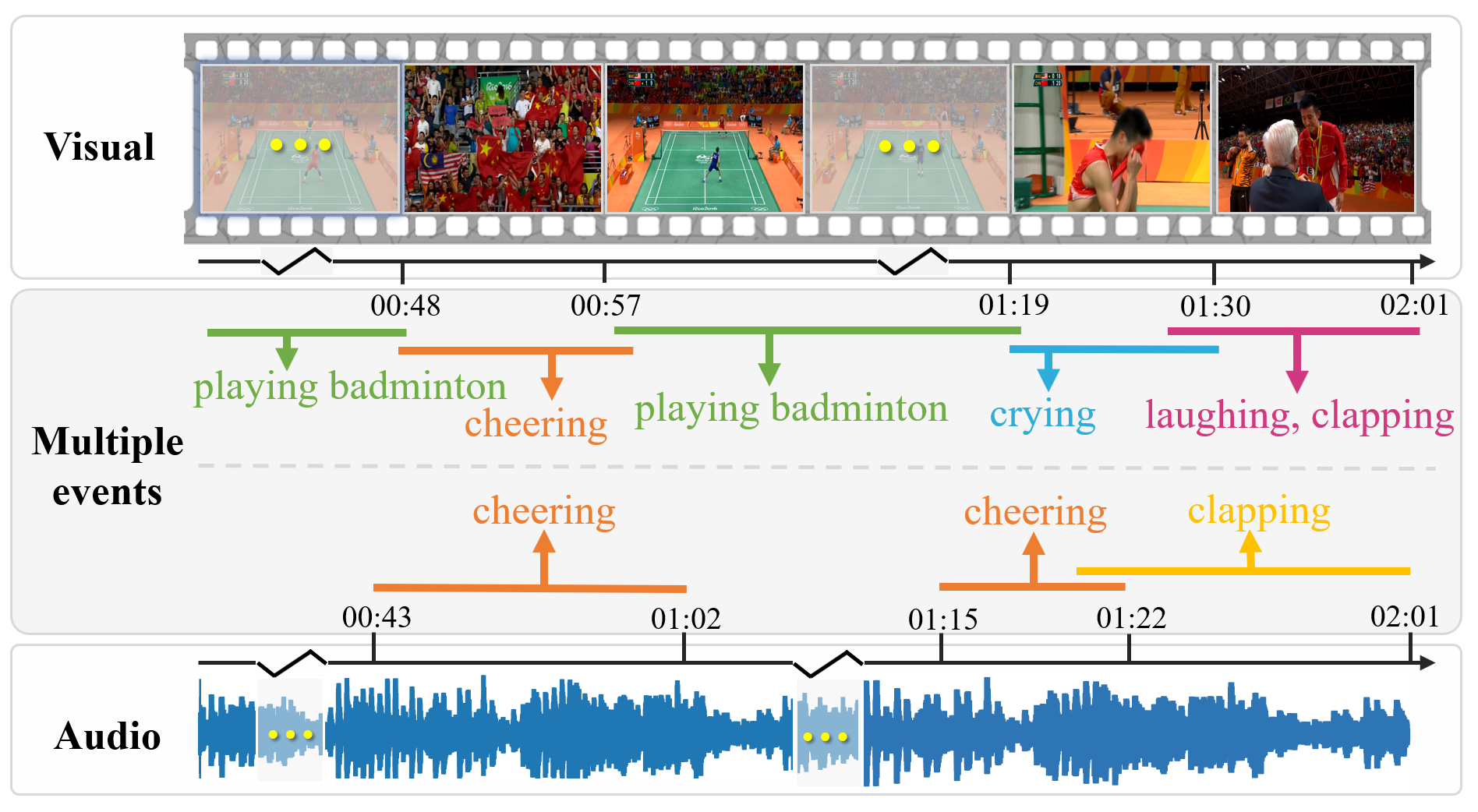
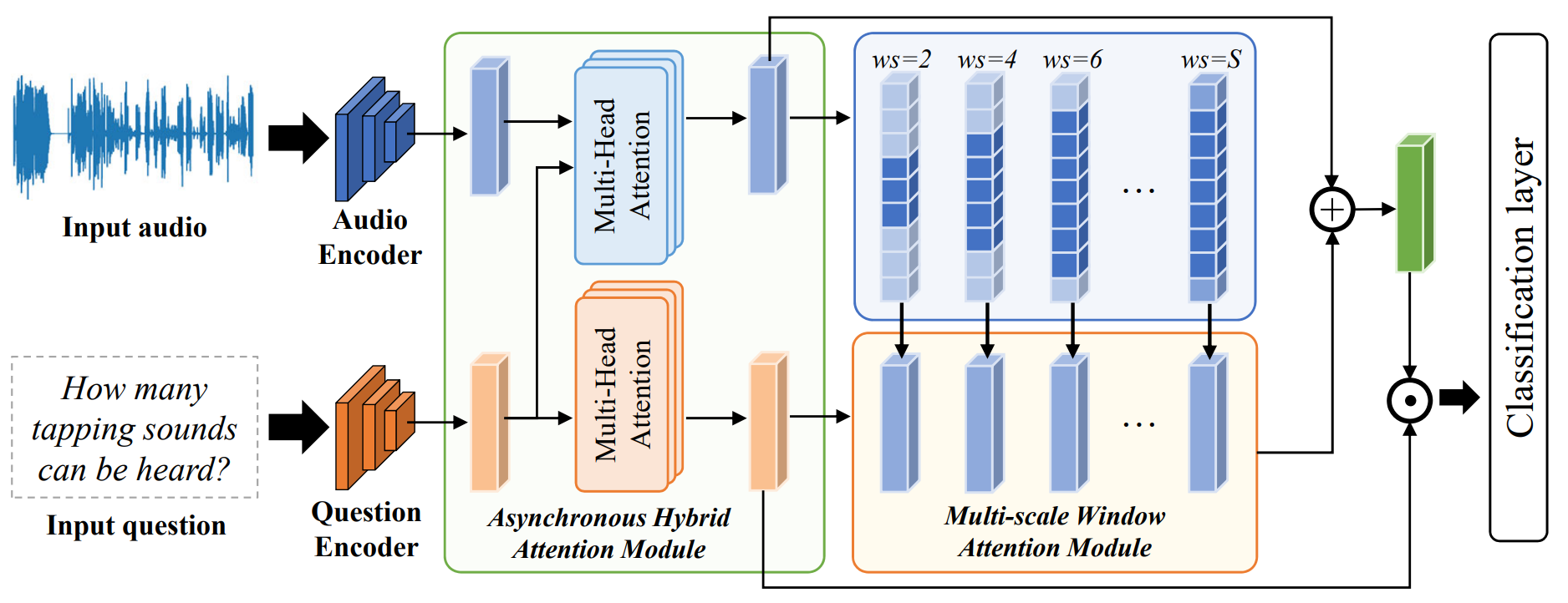
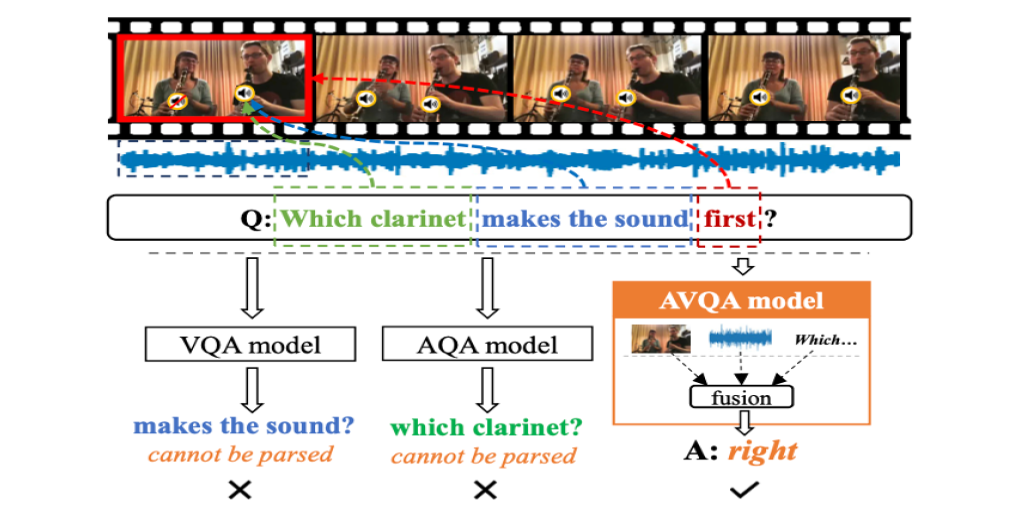
Progressive Spatio-temporal Perception for Audio-Visual Question Answering
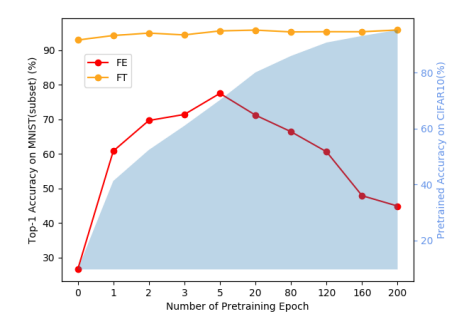
Towards Inadequately Pre-trained Models in Transfer Learning
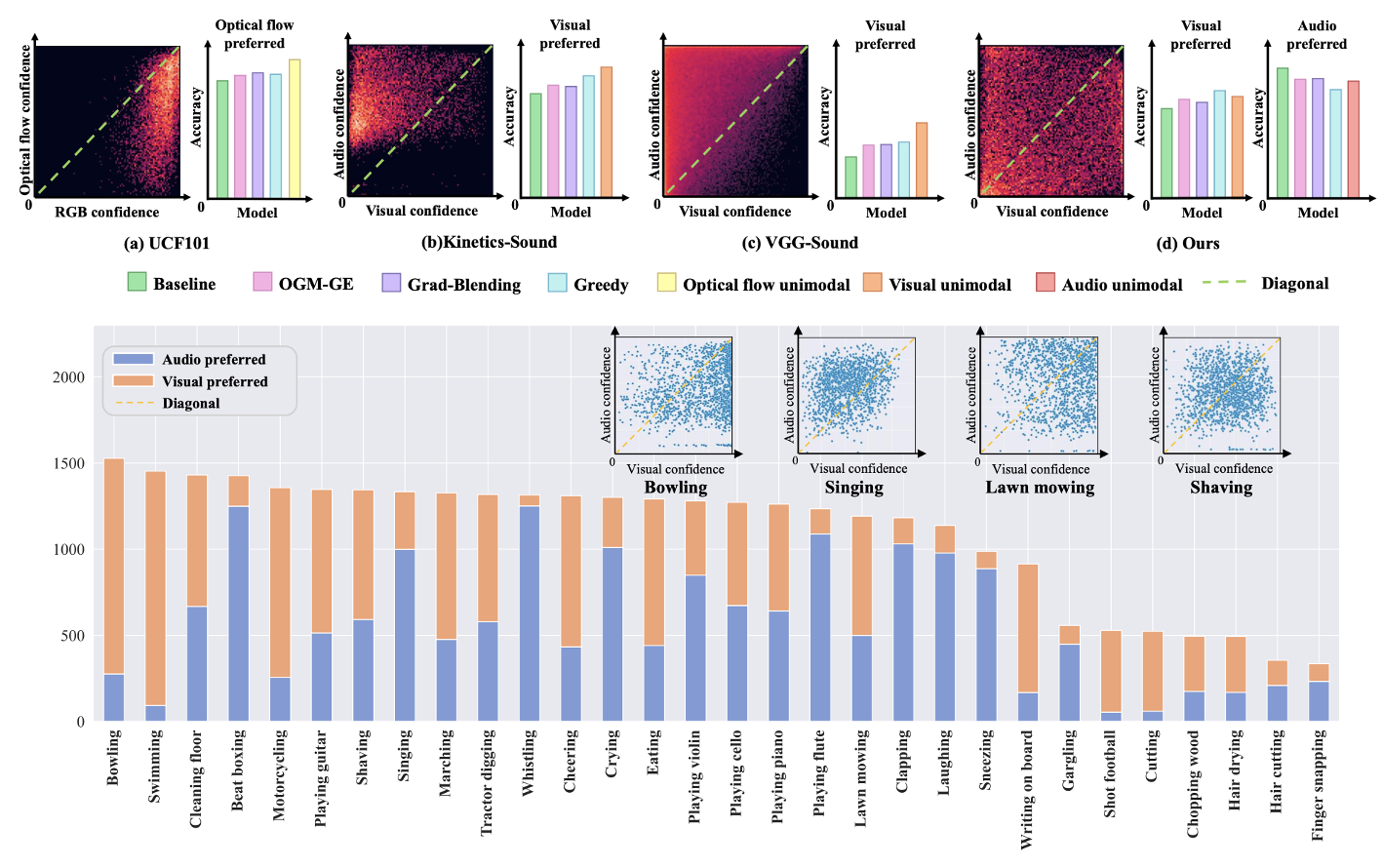
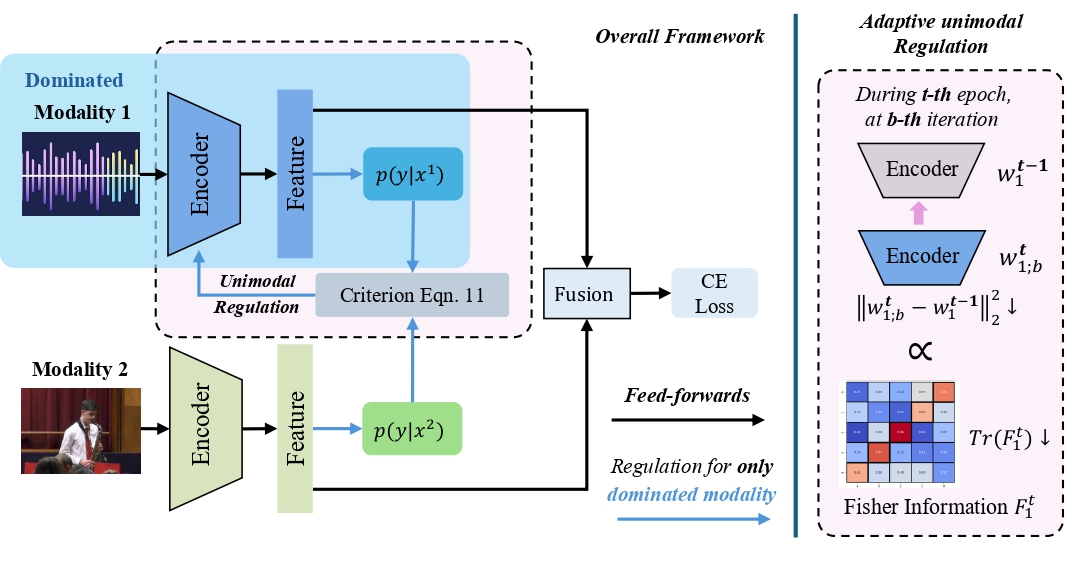
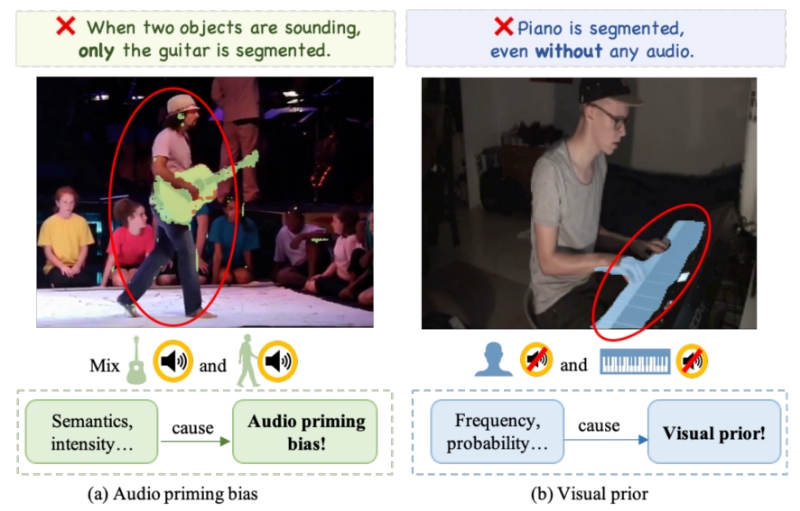
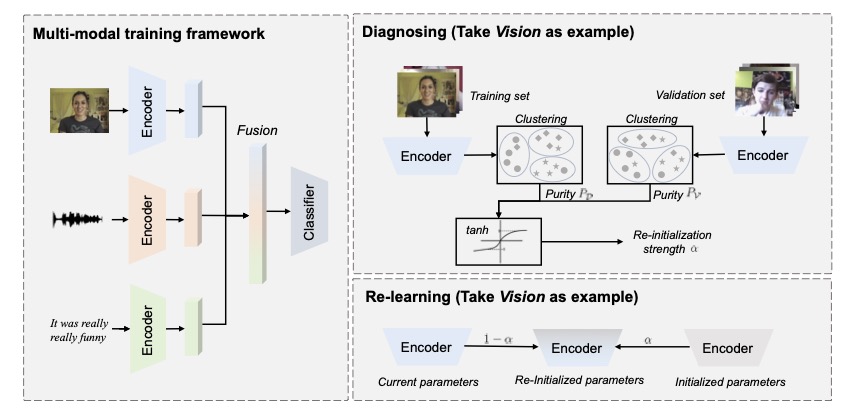
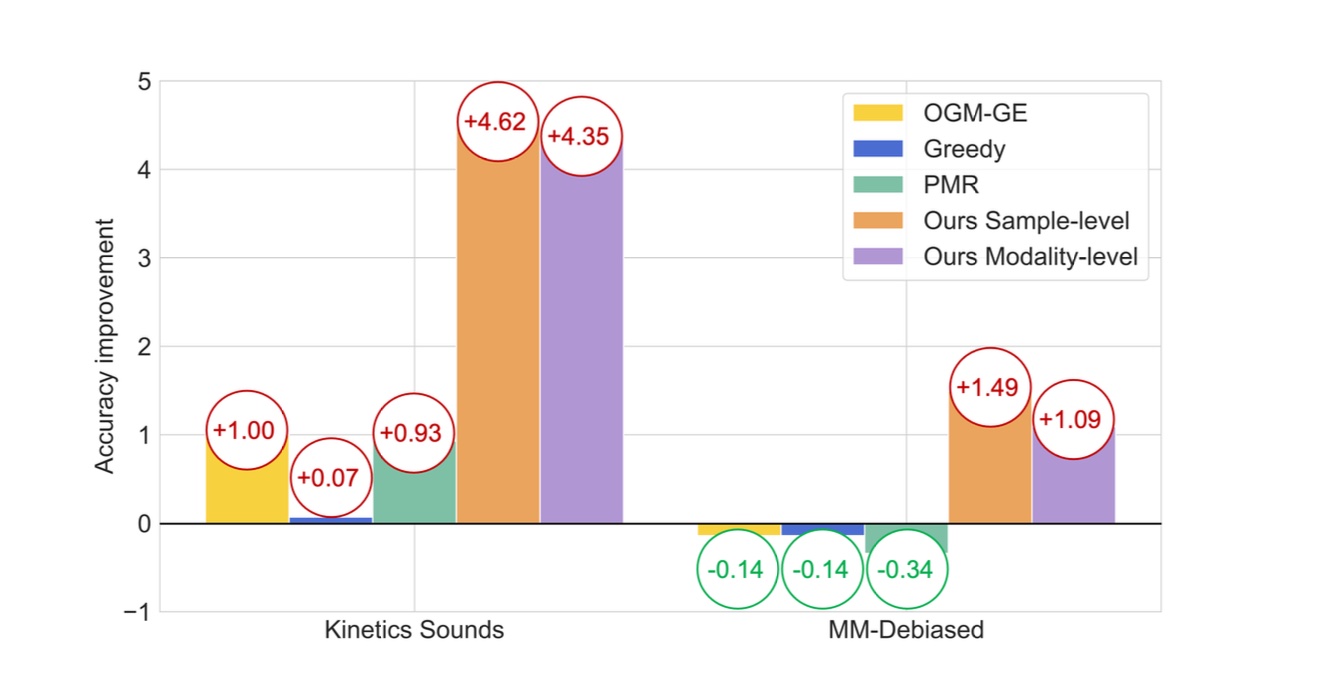
Balanced Audiovisual Dataset for Imbalance Analysis
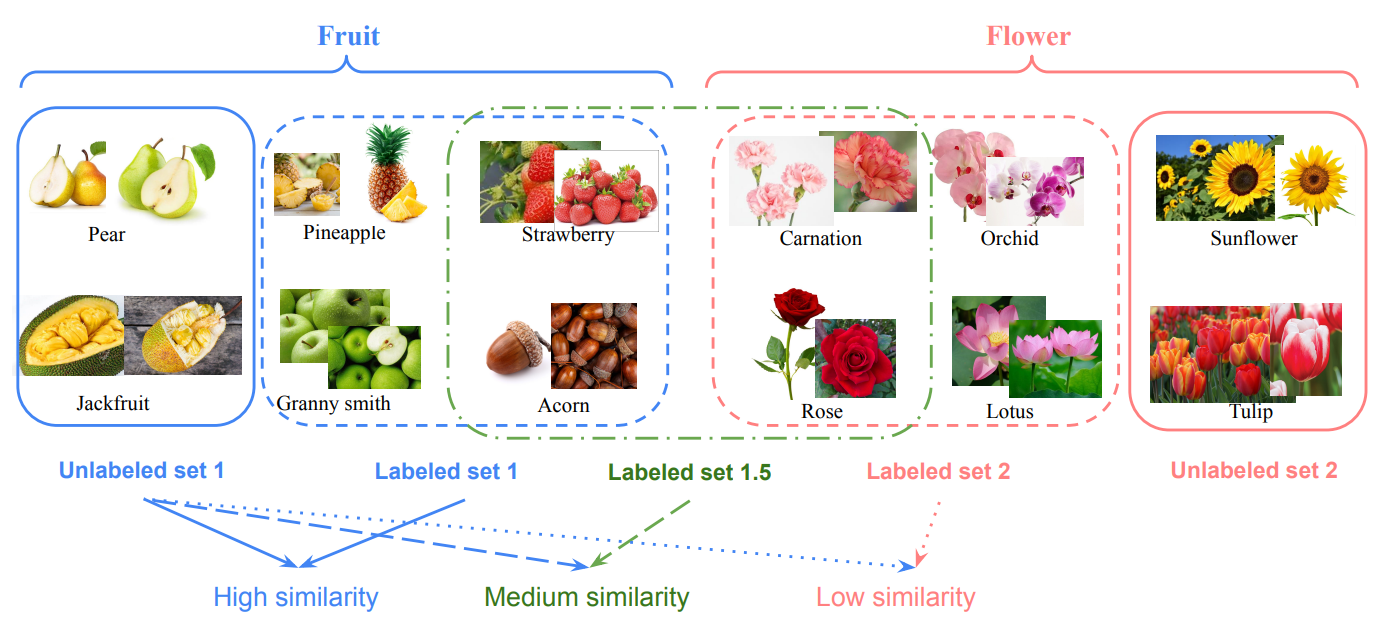
Supervised Knowledge May Hurt Novel Class Discovery Performance

Robust Cross-modal Knowledge Distillation for Unconstrained Videos
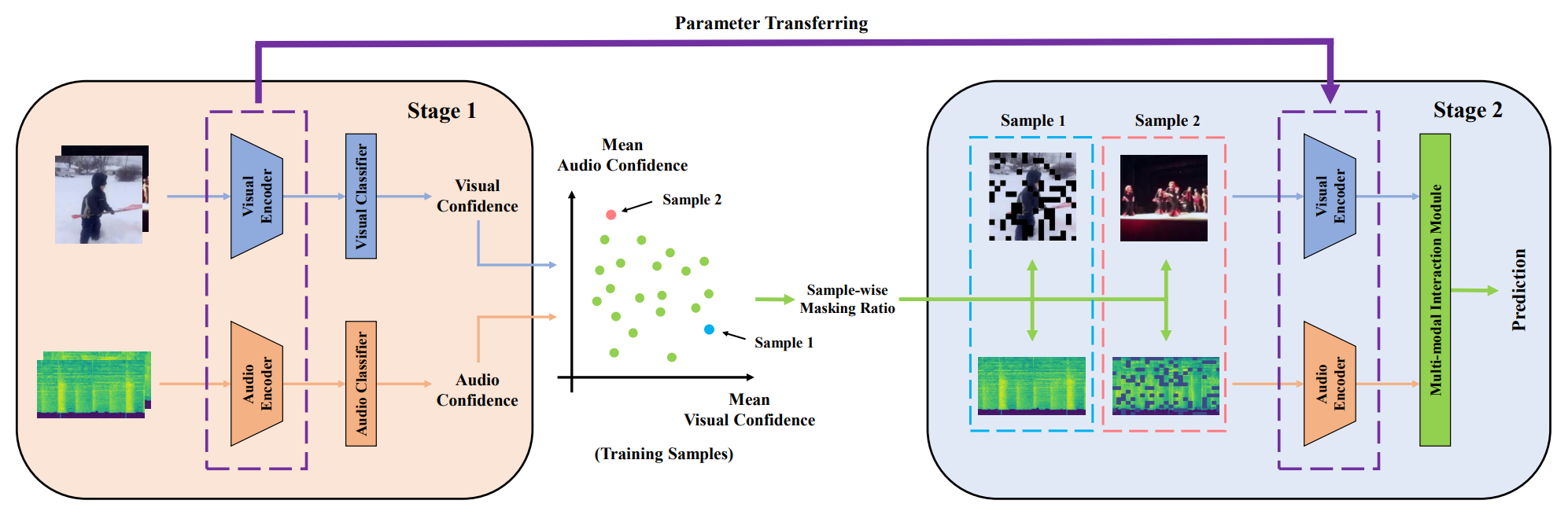
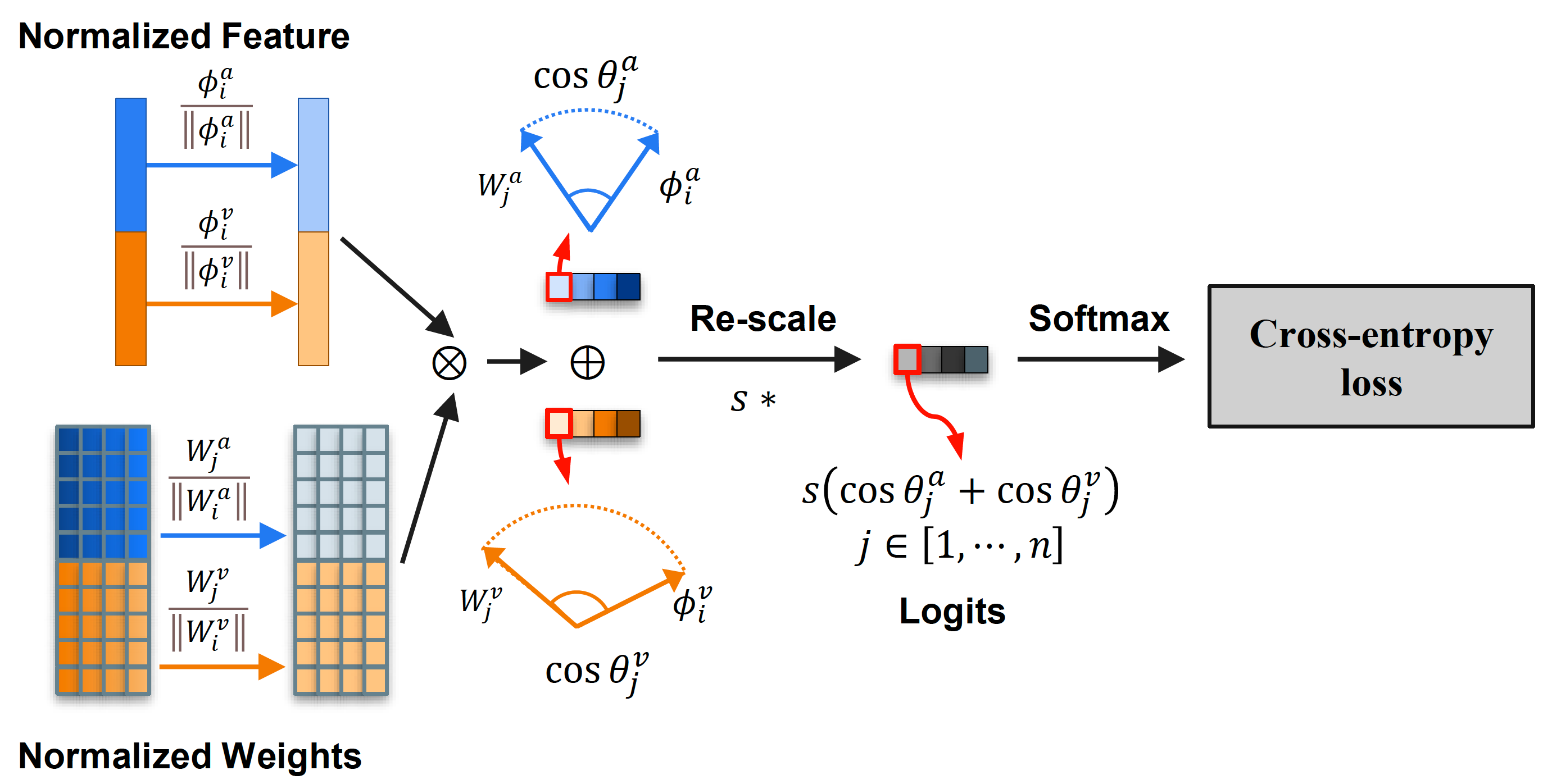

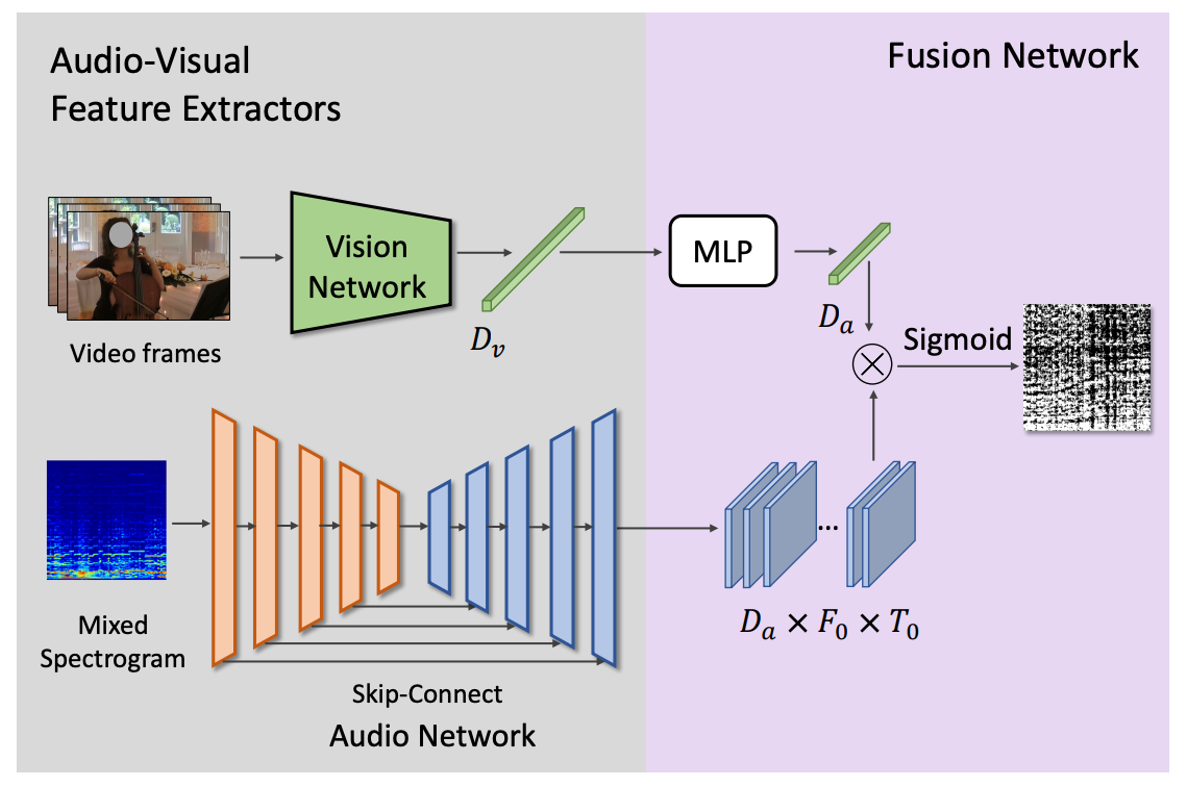
SeCo: Separating Unknown Musical Visual Sounds with Consistency Guidance
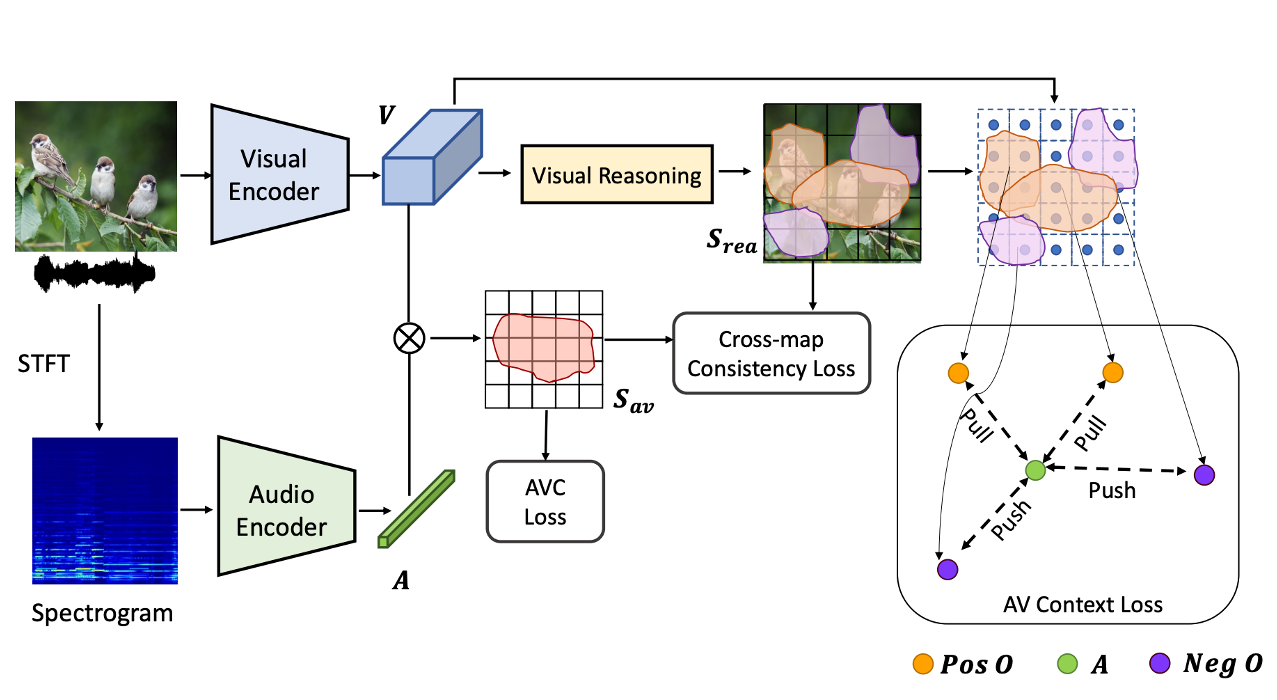
Exploiting Visual Context Semantics for Sound Source Localization
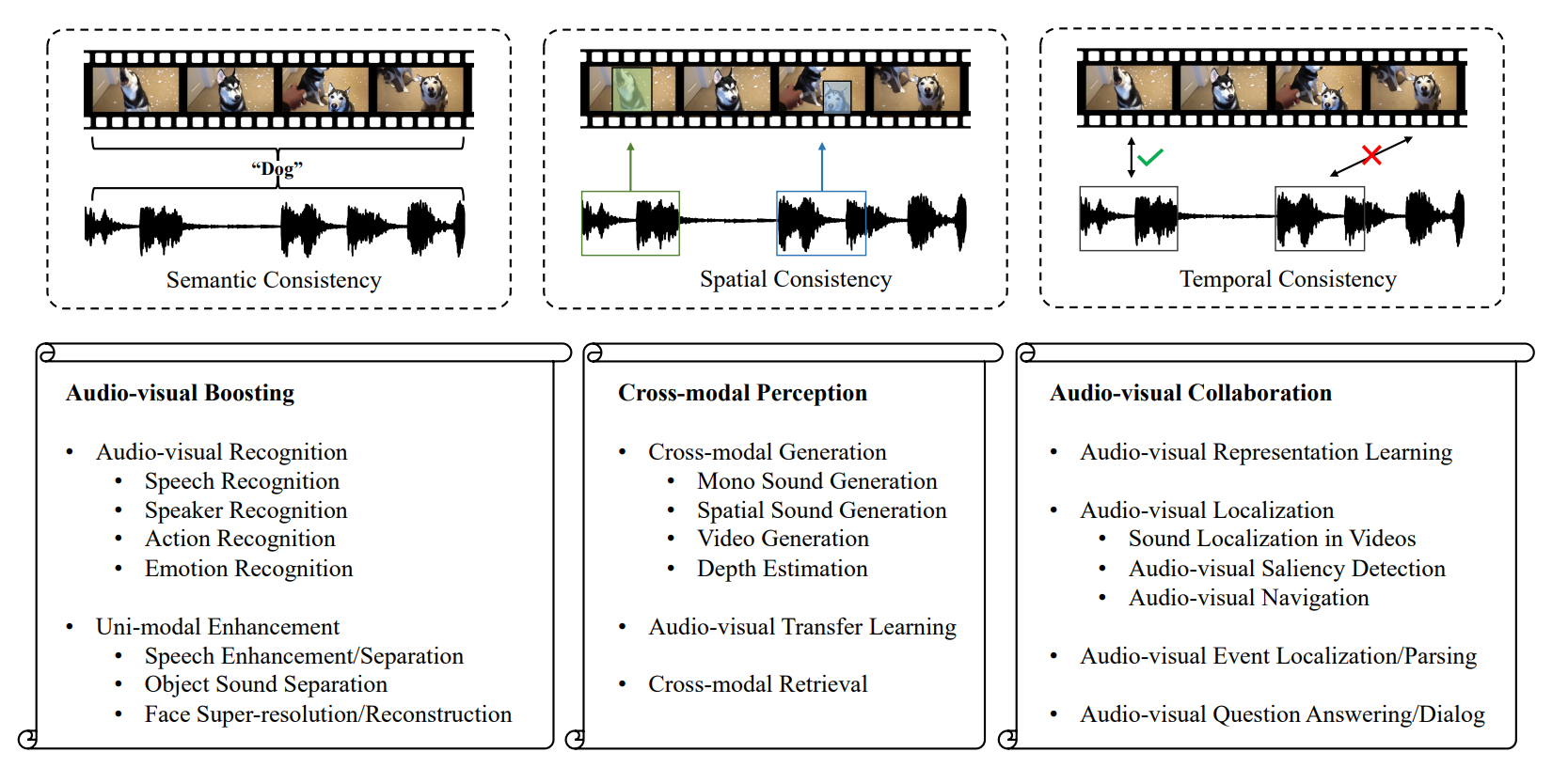
Self-supervised Learning for Heterogeneous Audiovisual Scene Analysis


Not All Knowledge Is Created Equal

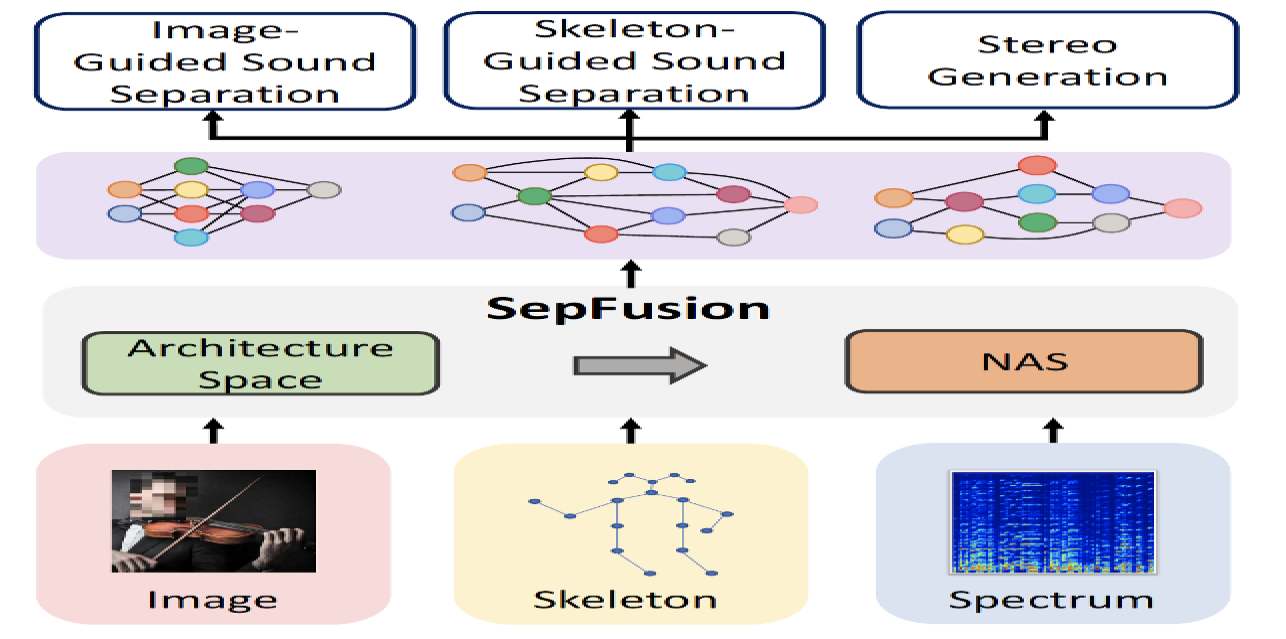
SepFusion: Finding Optimal Fusion Structures for Visual Sound Separation




Towards Accurate Knowledge Transfer via Target-awareness Representation Disentanglement
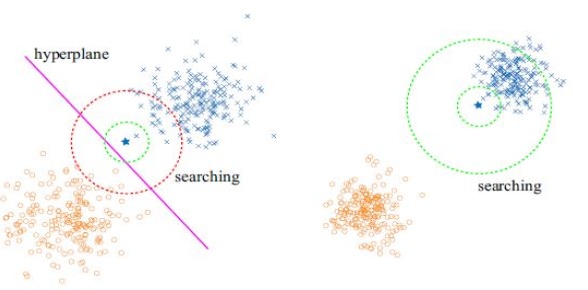
Generalising Combinatorial Discriminant Analysis through Conditioning Truncated Rayleigh Flow


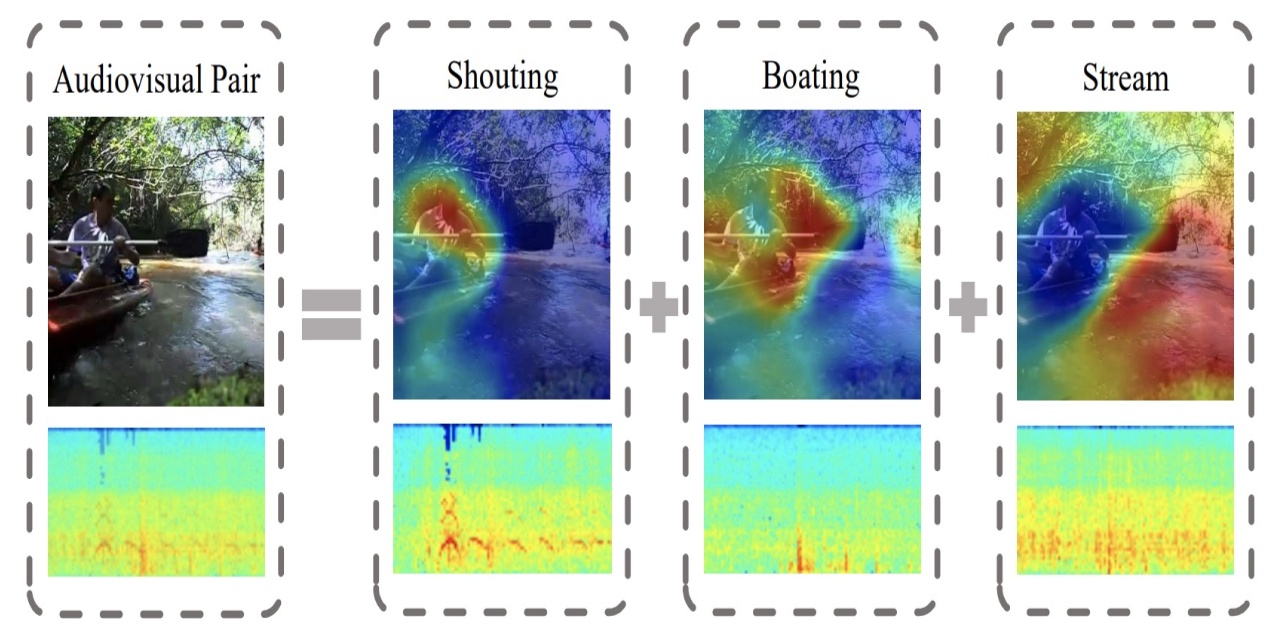
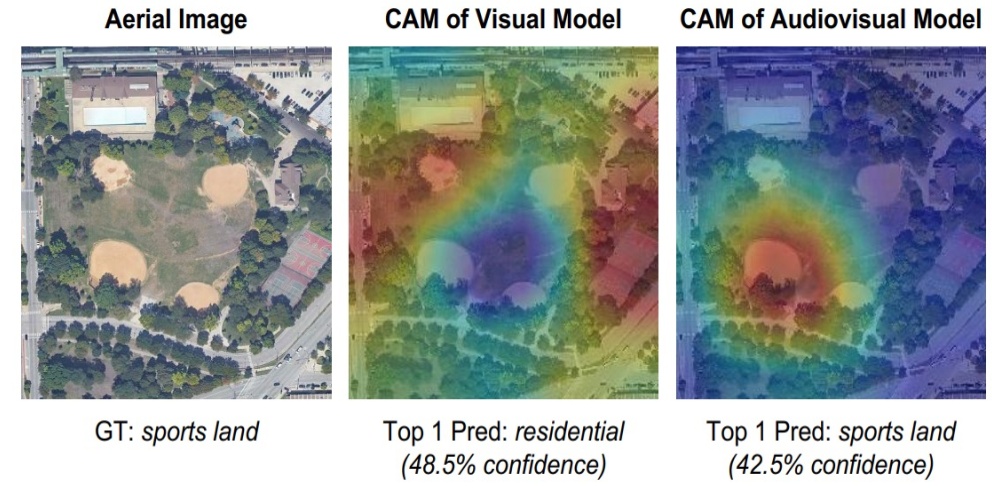



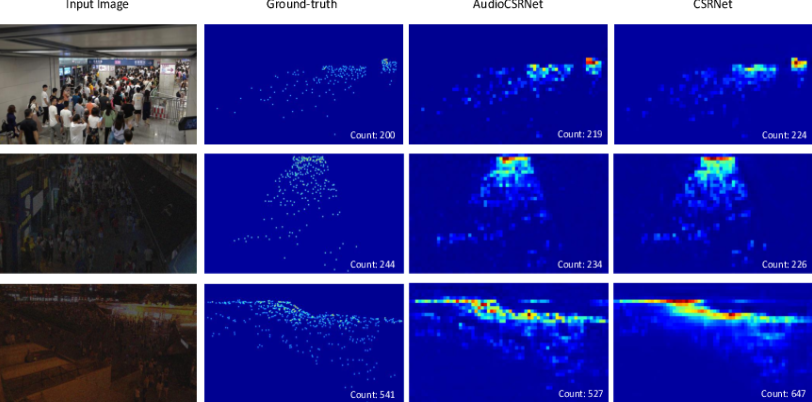

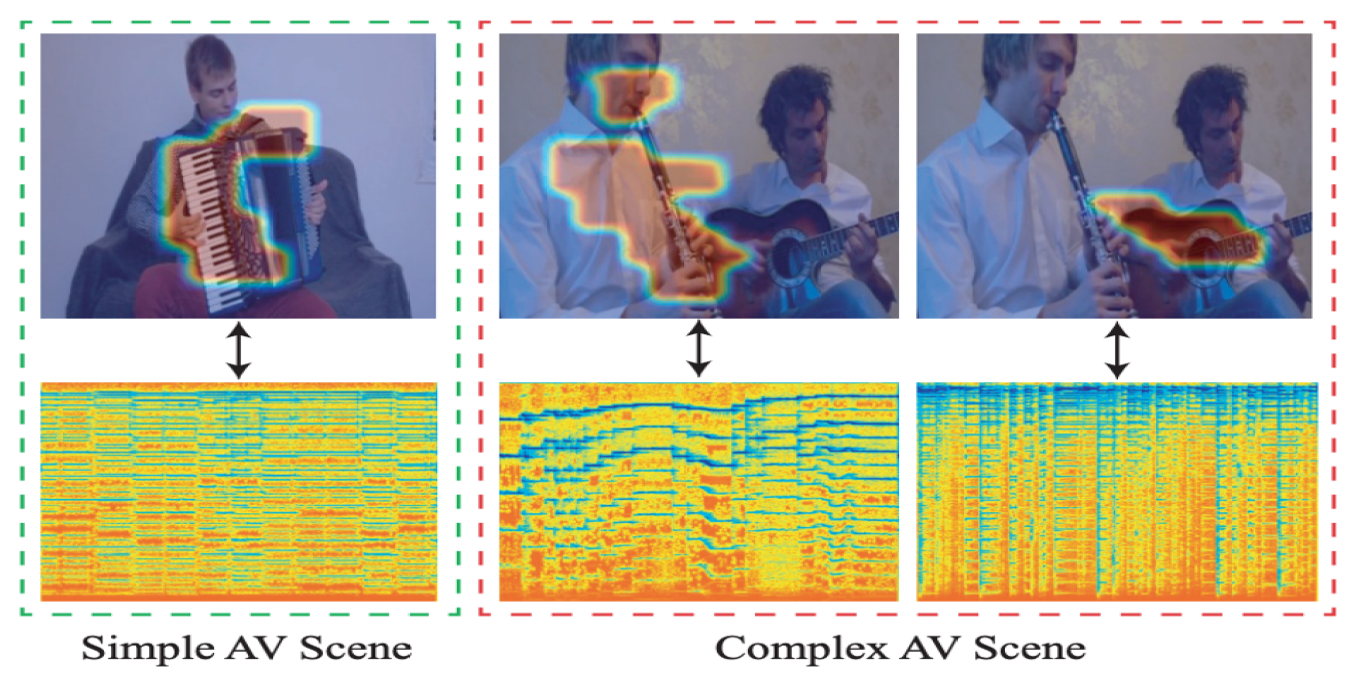
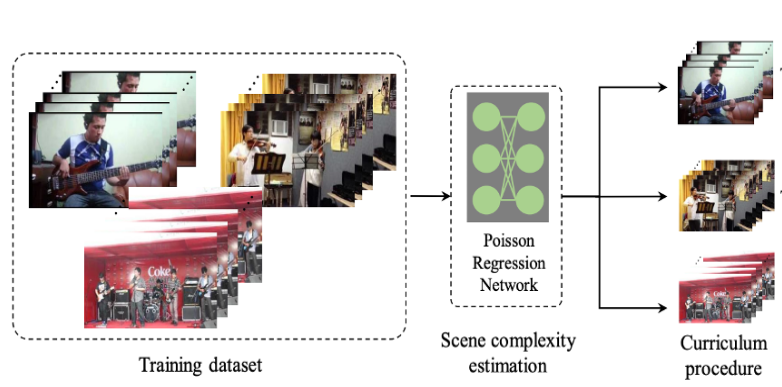
Curriculum Audiovisual Learning
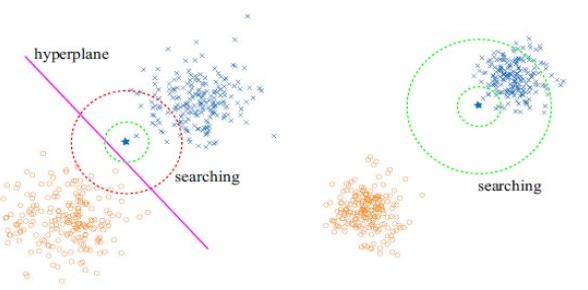
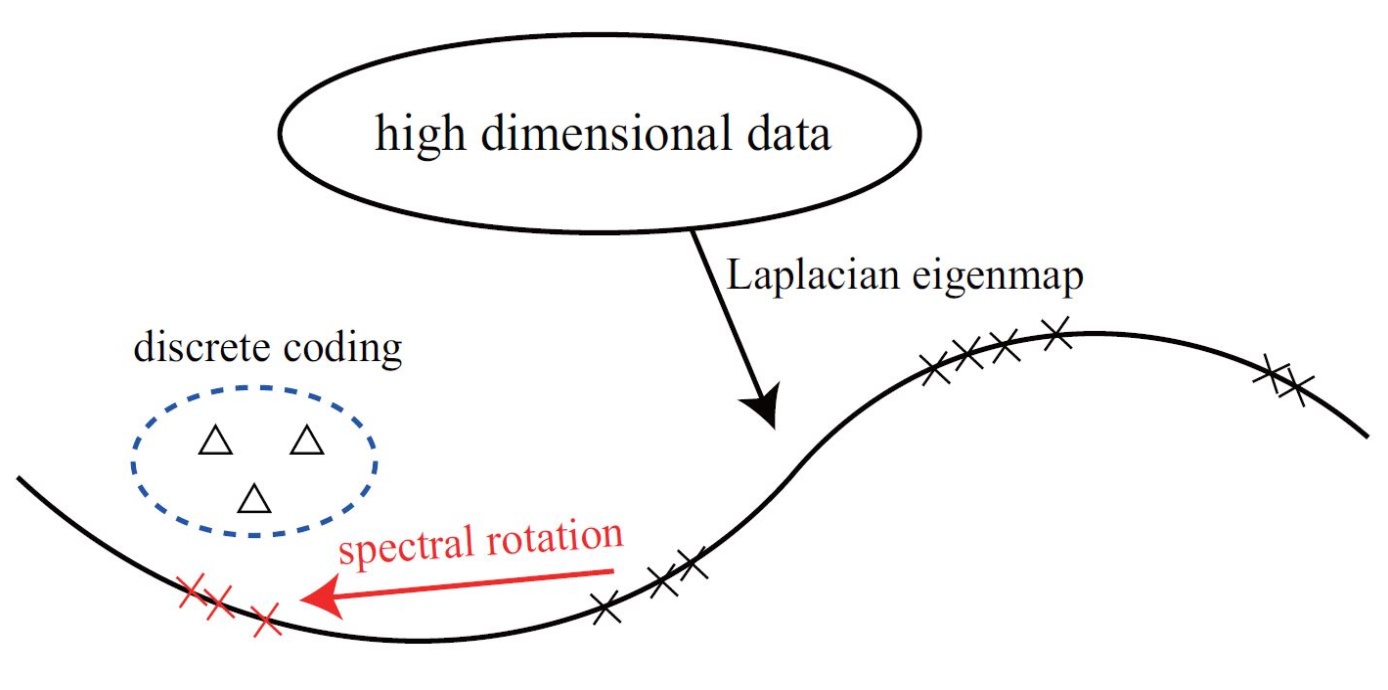
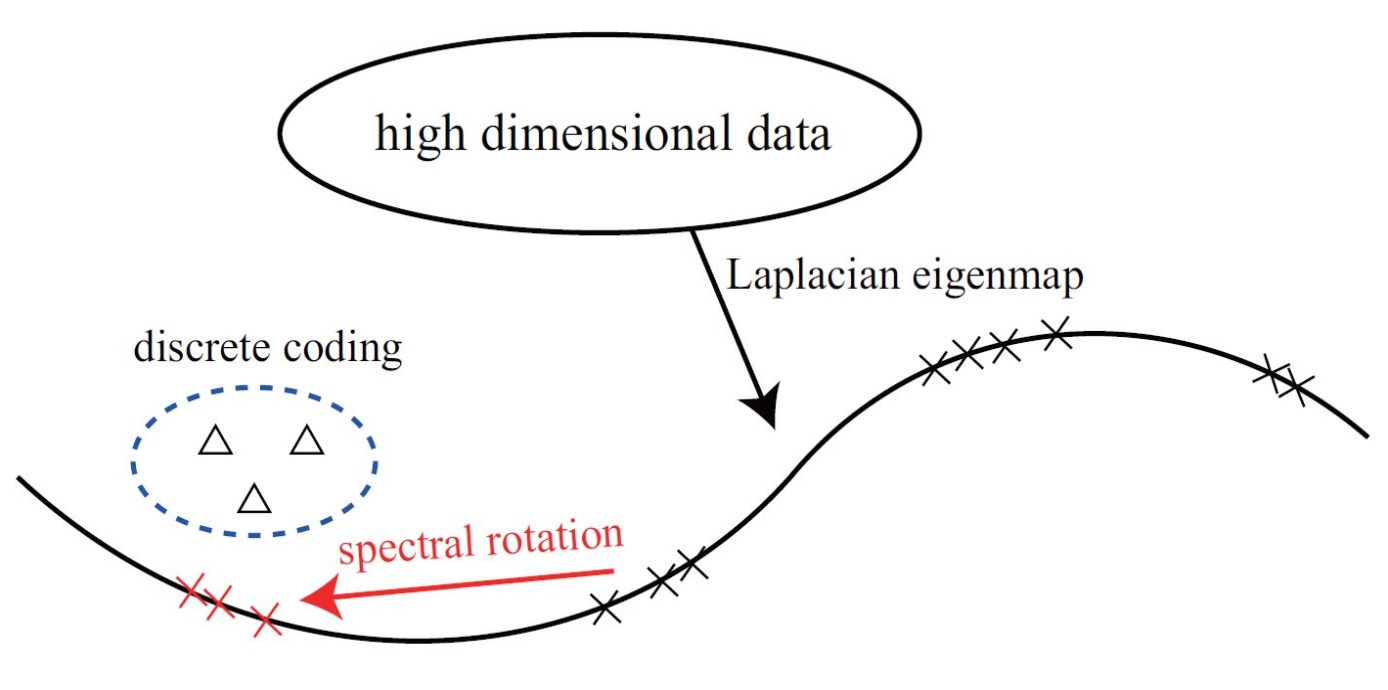
Discrete Spectral Hashing for Efficient Similarity Retrieval

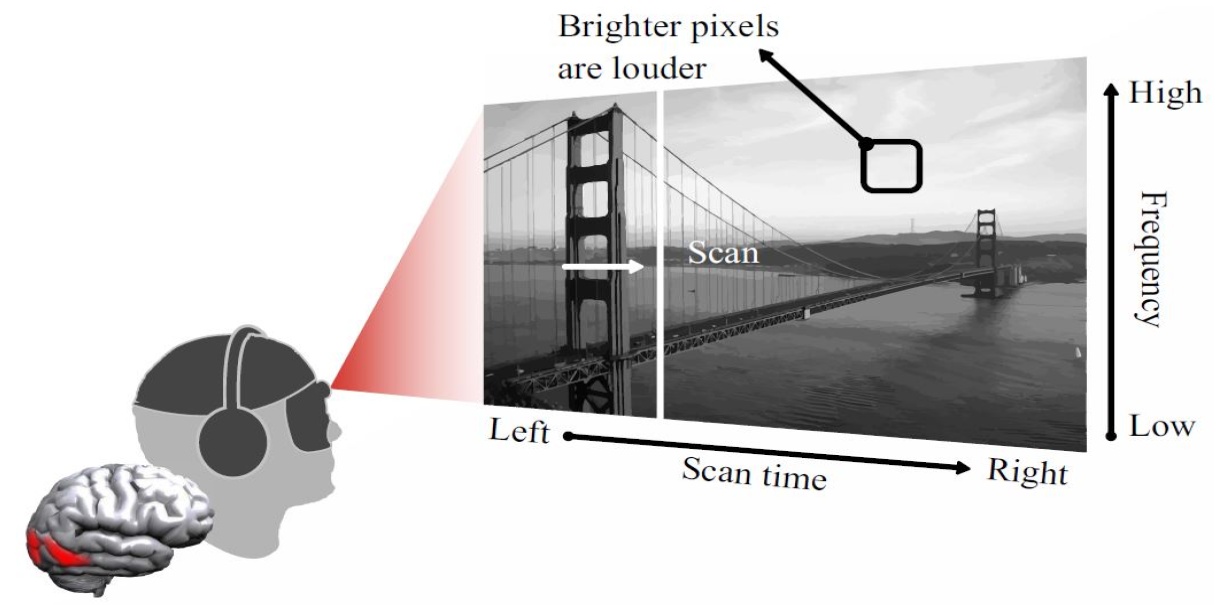
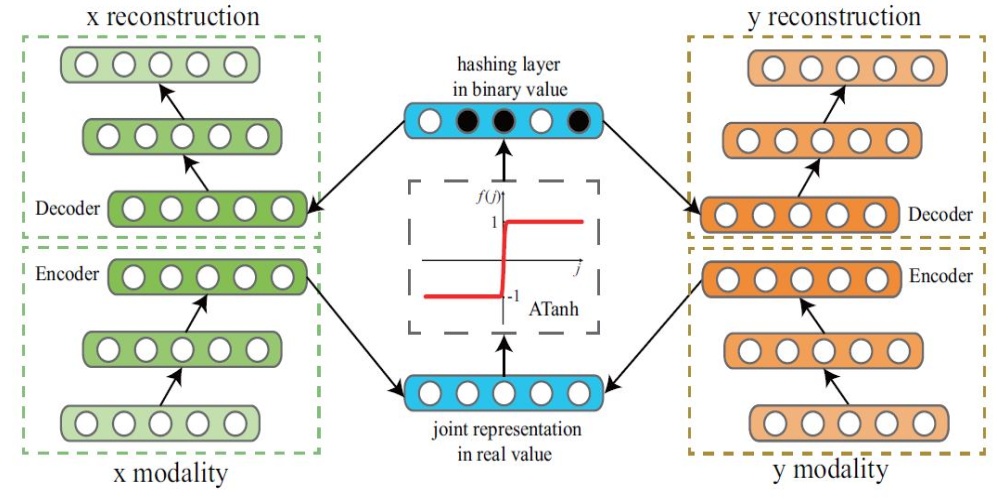
Deep Binary Reconstruction for Cross-modal Hashing
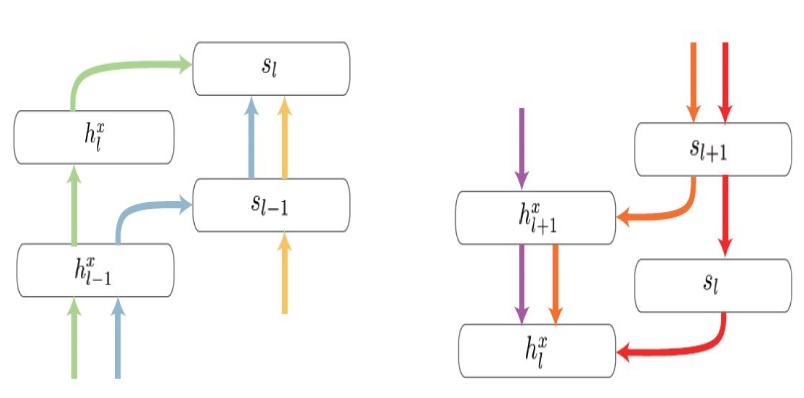
Dense Multimodal Fusion for Hierarchically Joint Representation



Temporal Multimodal Learning in Audiovisual Speech Recognition