Update
- 01 Jun 2022: The dataset has been uploaded to Google Drive, welcome to download and use!
- 28 Mar 2022: Camera-ready version has been released here!
- 22 Mar 2022: The MUSIC-AVQA dataset has been released, please see Download for details.
- 18 Mar 2022: Code has been released here!
- 08 Mar 2022: Watch the project's video demonstration on
YouTube or
Bilibili.
- 02 Mar 2022: Our paper is accepted for publication at CVPR2022. Camera-ready version and code will be released soon!
What is AVQA task?
We are surrounded by audio and visual messages in daily life, and both modalities jointly improve our ability in scene perception and understanding. For instance, imagining that we are in a concert, watching the performance and listening to the music at the same time contribute to better enjoyment of the show. Inspired by this, how to make machines integrate multimodal information, especially the natural modality such as the audio and visual ones, to achieve considerable scene perception and understanding ability as humans is an interesting and valuable topic. We focus on audio-visual question answering (AVQA) task, which aims to answer questions regarding different visual objects, sounds, and their associations in videos. The problem requires comprehensive multimodal understanding and spatio-temporal reasoning over audio-visual scenes.
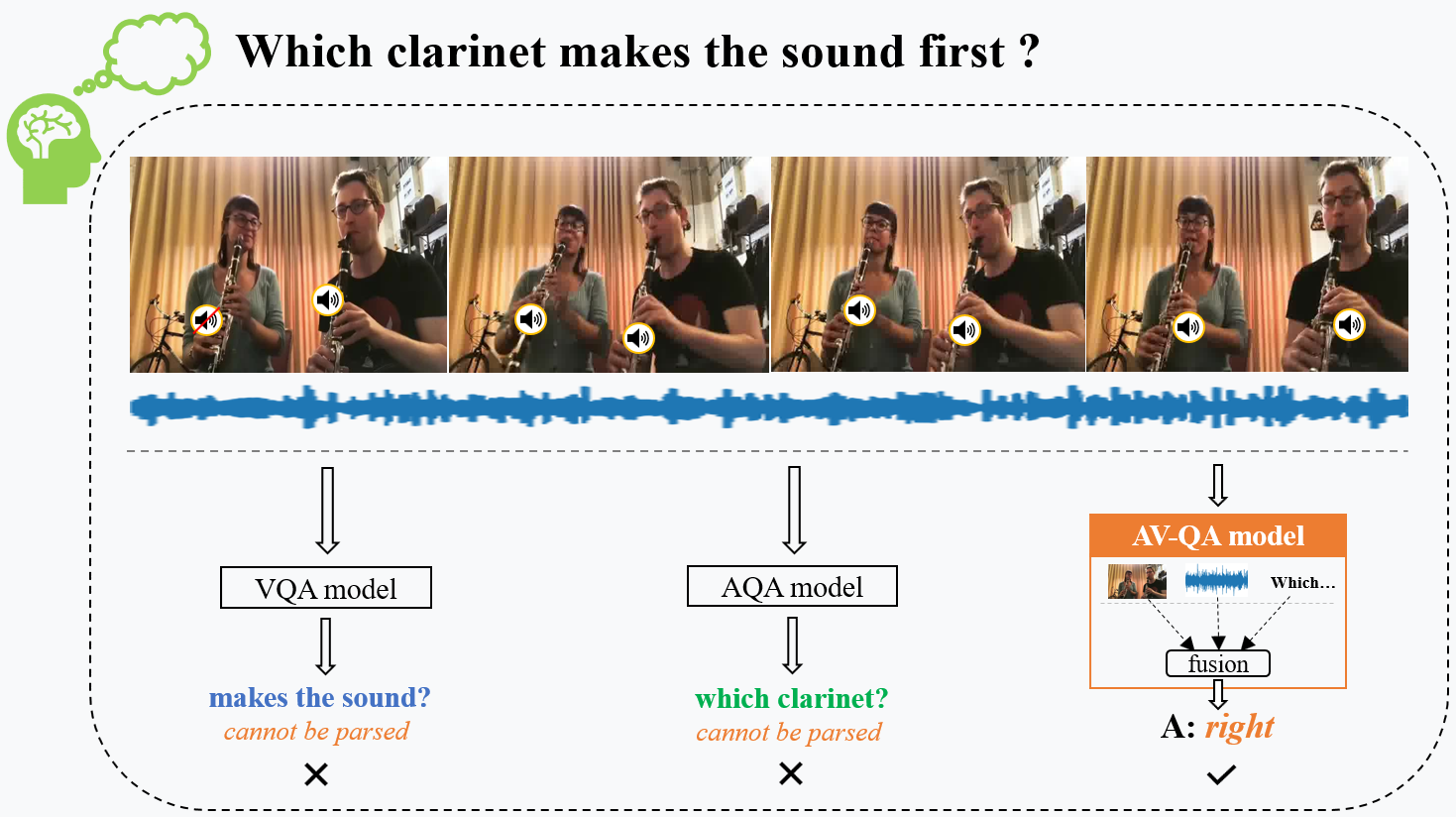
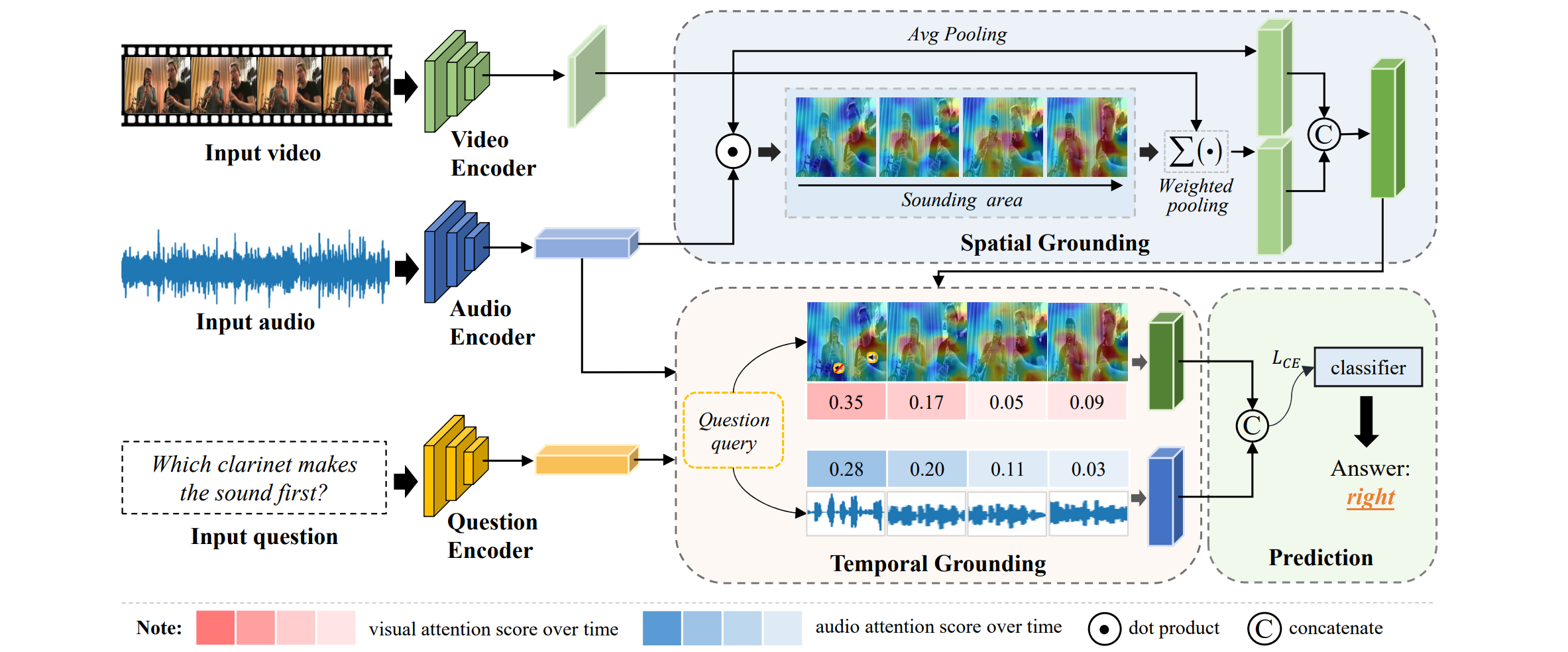
For instance, as shown in this Figure, when answering the audio-visual question “Which clarinet makes the sound first” for this instrumental ensemble, it requires to locate sounding objects “clarinet” in the audio-visual scenario and focus on the “first” sounding “clarinet” in the timeline. To answer the question correctly, both effective audio-visual scene understanding and spatio-temporal reasoning are essentially desired.
Audio-visual question answering requires auditory and visual modalities for multimodal scene understanding and spatiotemporal reasoning. For example, when we encounter a complex musical performance scene involving multiple sounding and nonsounding instruments above, it is difficult to analyze the sound first term in the question by VQA model that only considers visual modality. While if we only consider the AQA model with mono sound, the left or right position is also hard to be recognized. However, we can see that using both auditory and visual modalities can answer this question effortlessly.
What is MUSIC-AVQA dataset?
To explore scene understanding and spatio-temporal reasoning over audio and visual modalities, we build a largescale audio-visual dataset, MUSIC-AVQA, which focuses on question-answering task. As noted above, high-quality datasets are of considerable value for AVQA research.
Why musical performance? Considering that musical performance is a typical multimodal scene consisting of abundant audio and visual components as well as their interaction, it is appropriate to be utilized for the exploration of effective audio-visual scene understanding and reasoning.
Basic informations
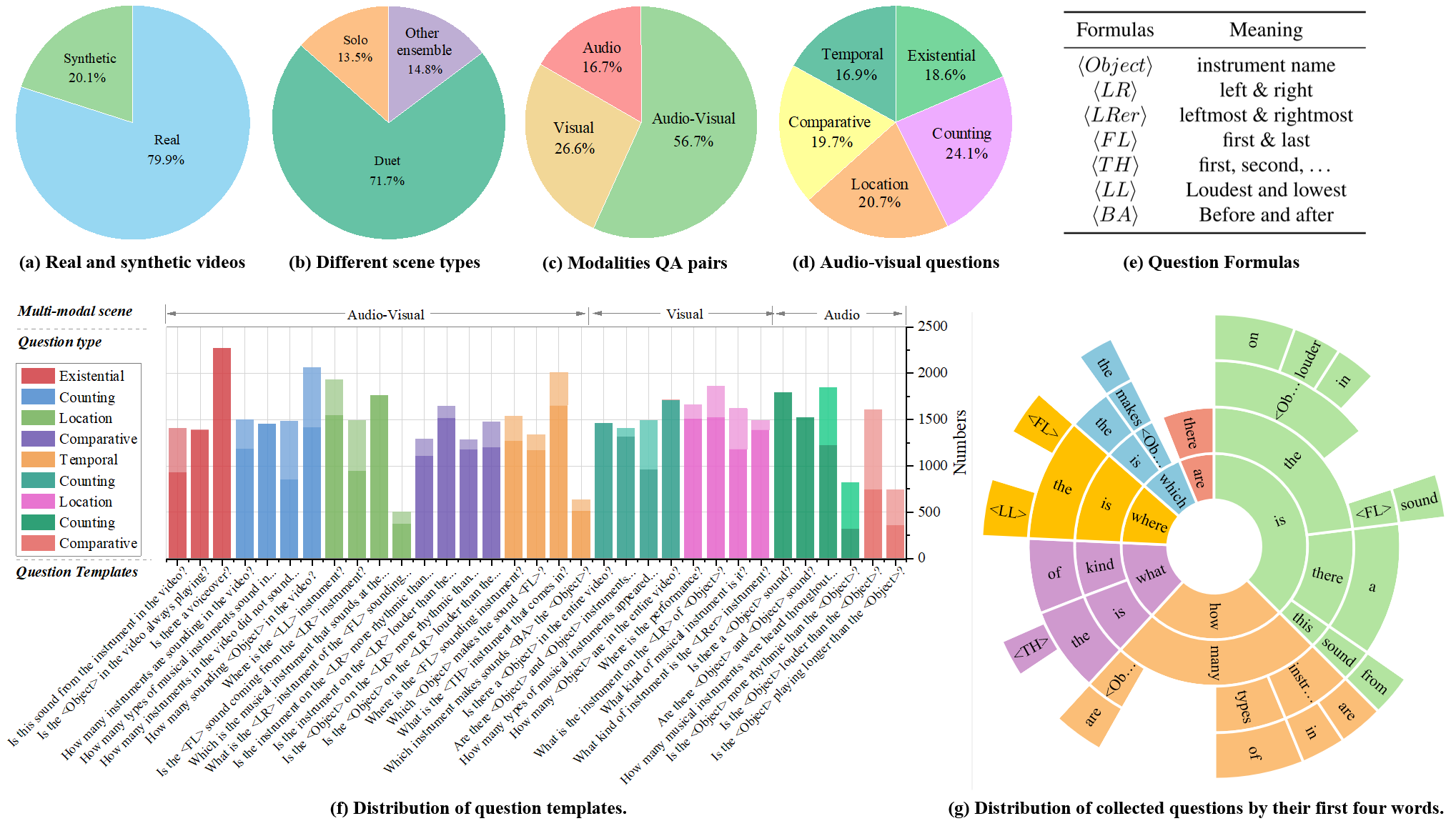
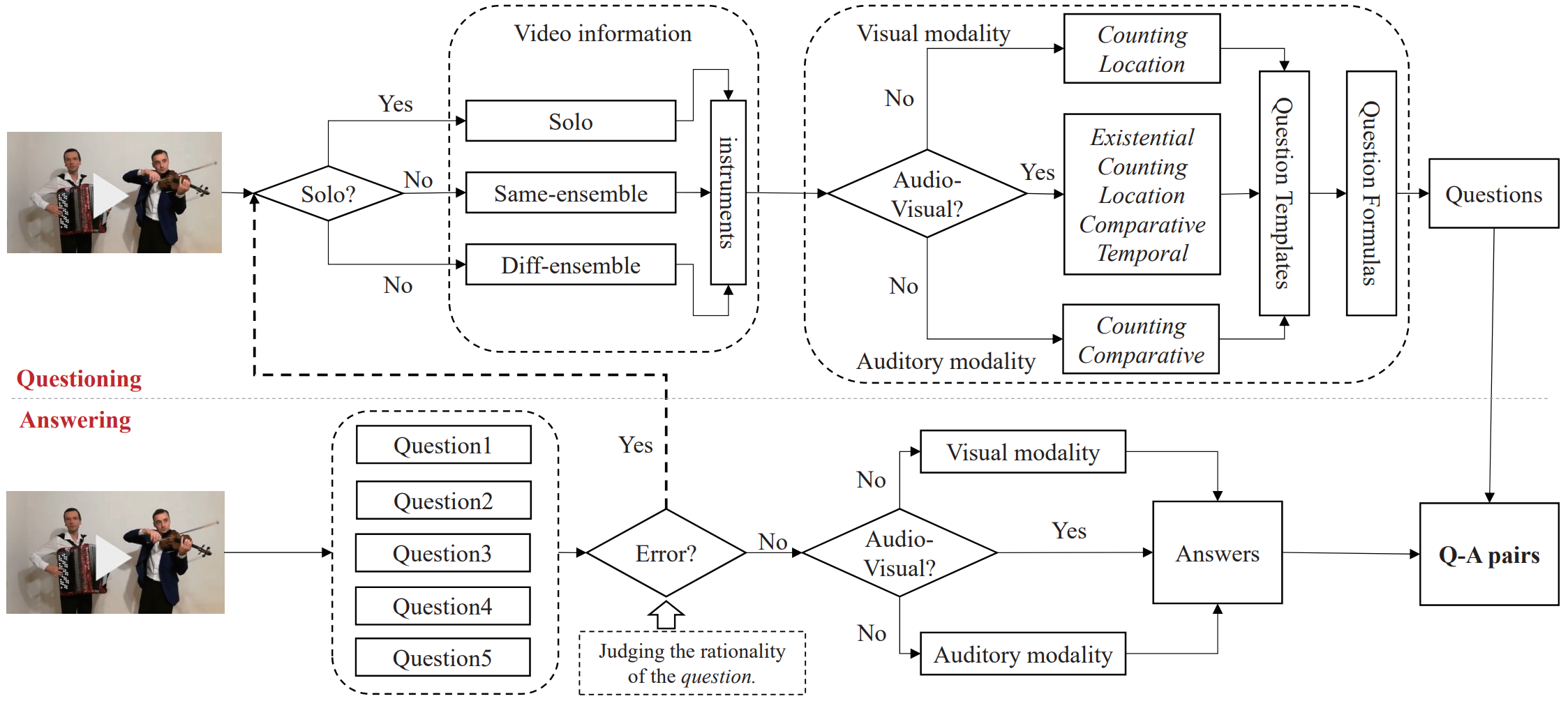
We choose to manually collect amounts of musical performance videos from YouTube. Specifically, 22 kinds of instruments, such as guitar, cello, and xylophone, are selected and 9 audio-visual question types are accordingly designed, which cover three different scenarios, i.e., audio, visual and audio-visual. Annotations are collected using a novel by our GSAI-Labeled system.
Characteristics
- 3 typical multimodal scene
- 22 kinds of instruments
- 4 categories: String, Wind, Percussion and Keyboard.
- 9,290 videos for over 150 hours
- 7,423 real videos
- 1,867 synthetic videos
- 9 audio-visual question types
- 45,867 question-answer pairs
- Diversity, complexity and dynamic
Personal data/Human subjects
Videos in MUSIC-AVQA are public on YouTube, and annotated via crowdsourcing. We have explained how the data would be used to crowdworkers. Our dataset does not contain personally identifiable information or offensive content.



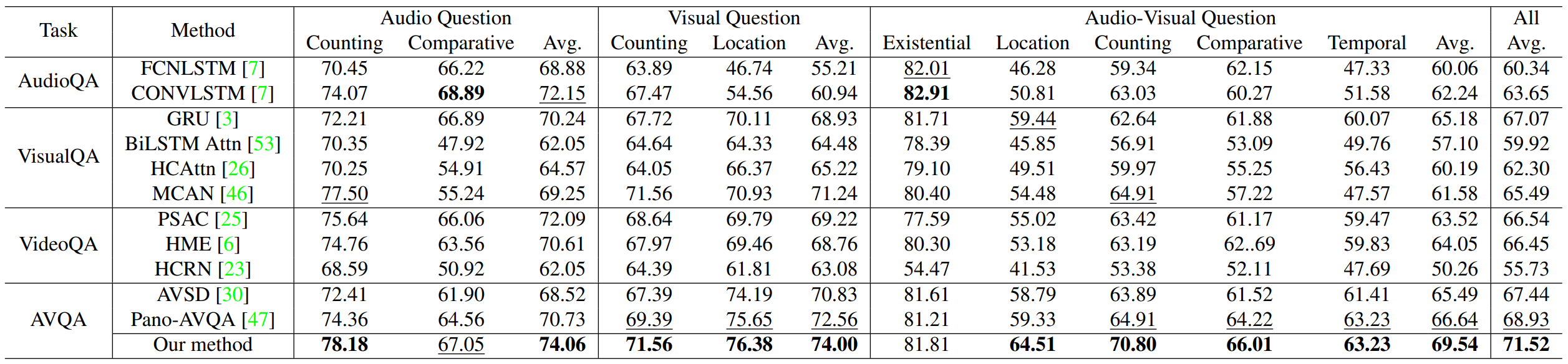
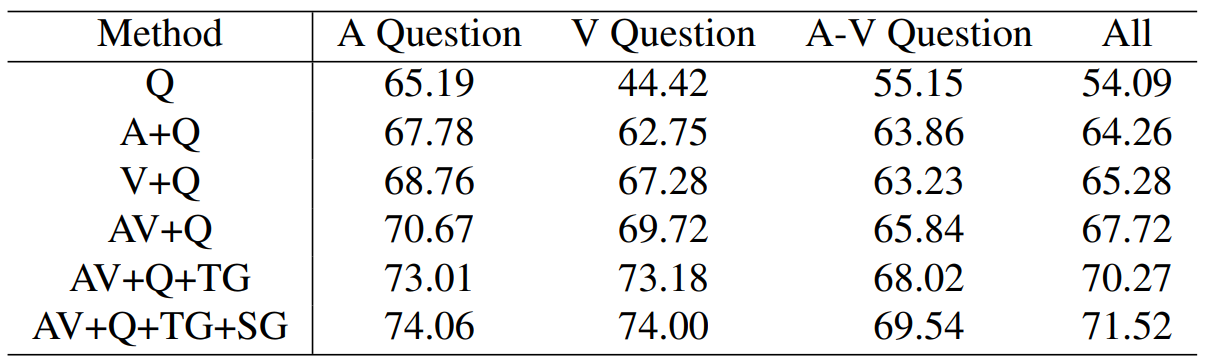 As shown in right table, we observe that leveraging audio, visual, and question information can boost AVQA task.
The below table shows that audio-visual video questiFon answering results of different methods on the test set of MUSIC-AVQA. And the top-2 results are highlighted.
As shown in right table, we observe that leveraging audio, visual, and question information can boost AVQA task.
The below table shows that audio-visual video questiFon answering results of different methods on the test set of MUSIC-AVQA. And the top-2 results are highlighted.