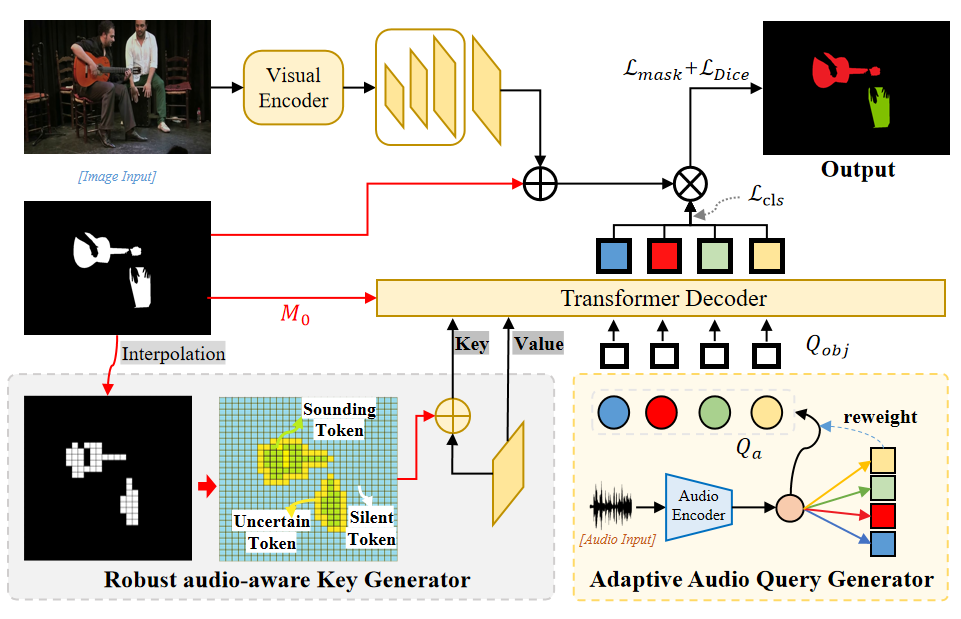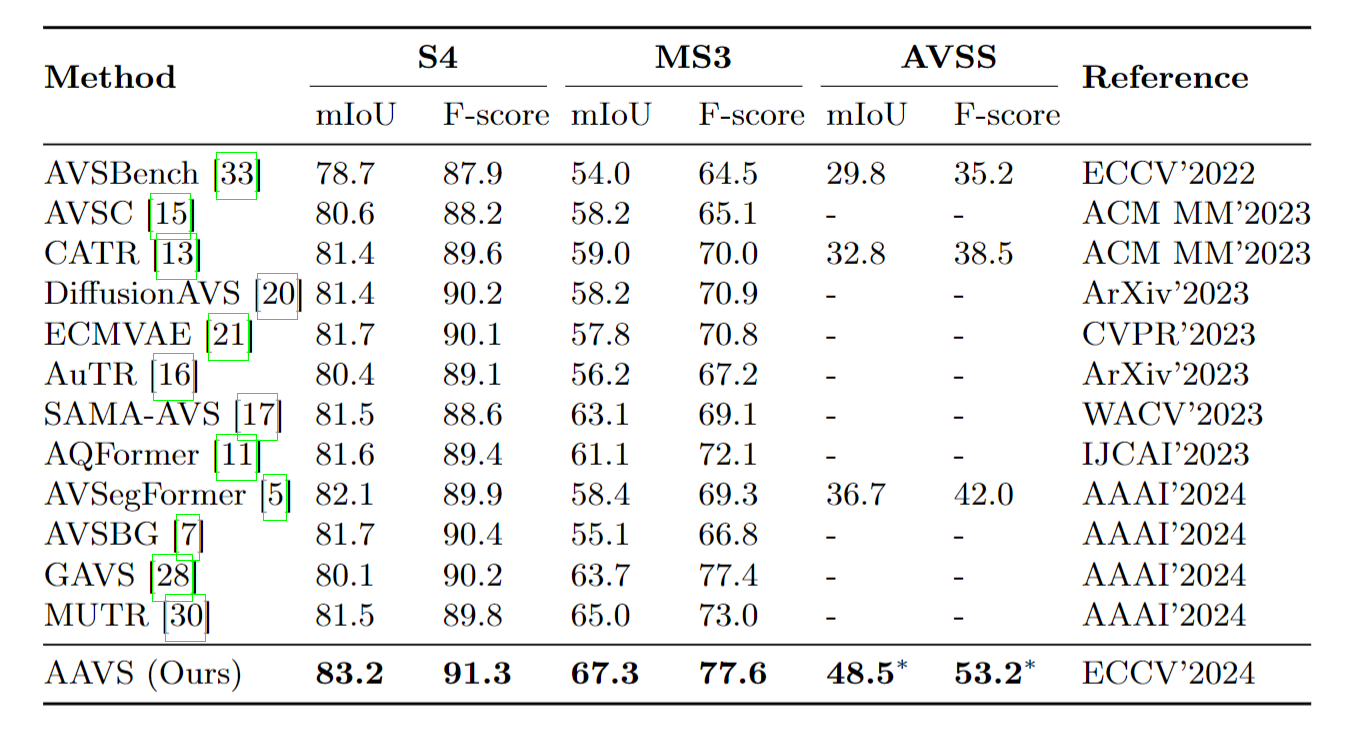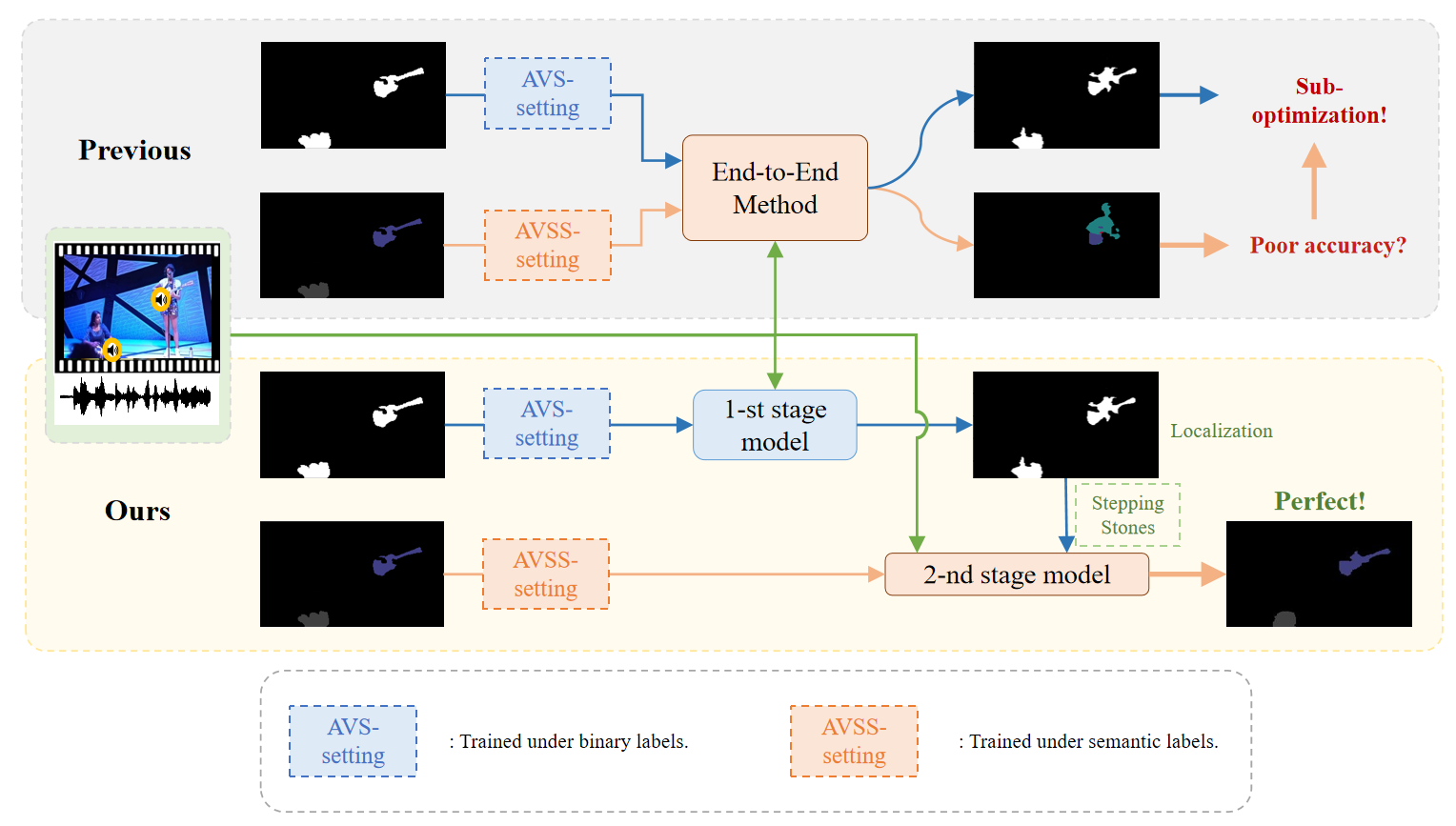
Audio-Visual Segmentation (AVS) aims to achieve pixel-level localization of sound sources in videos, while Audio-Visual Semantic Segmentation (AVSS), as an extension of AVS, further pursues semantic understanding of audio-visual scenes. However, since the AVSS task requires the establishment of audio-visual correspondence and semantic understanding simultaneously, we observe that previous methods have struggled to handle this mashup of objectives in end-to-end training, resulting in insufficient learning and sub-optimization. Therefore, we propose a two-stage training strategy called Stepping Stones, which decomposes the AVSS task into two simple subtasks from localization to semantic understanding, which are fully optimized in each stage to achieve step-by-step global optimization. This training strategy has also proved its generalization and effectiveness on existing methods. To further improve the performance of AVS tasks, we propose a novel framework Adaptive Audio Visual Segmentation, in which we incorporate an adaptive audio query generator and integrate masked attention into the transformer decoder, facilitating the adaptive fusion of visual and audio features. Extensive experiments demonstrate that our methods achieve state-of-the-art results on all three AVS benchmarks..



Video cases will be updated soon.
@article{ma2024steppingstones,
title={Stepping Stones: A Progressive Training Strategy for Audio-Visual Semantic Segmentation},
author={Ma, Juncheng and Sun, Peiwen and Wang, Yaoting and Hu, Di},
journal={IEEE European Conference on Computer Vision (ECCV)},
year={2024},
}