Introduction
The imbalance problem is widespread in the field of machine learning, which also exists in multimodal learning areas where models tend to rely on the dominant modality in the presence of discrepancies between modalities.
Despite Recent studies have endeavored to address the issue of modality imbalance, we observe that although existing imbalance methods exhibit superior performance on the overall testing set, they even fail to perform better than the unimodal model when inference on some modality-preferred subsets.This phenomenon has not been adequately addressed in prior works but it may impact the reliability of multimodal models in certain scenarios, such as those involving modality noise.
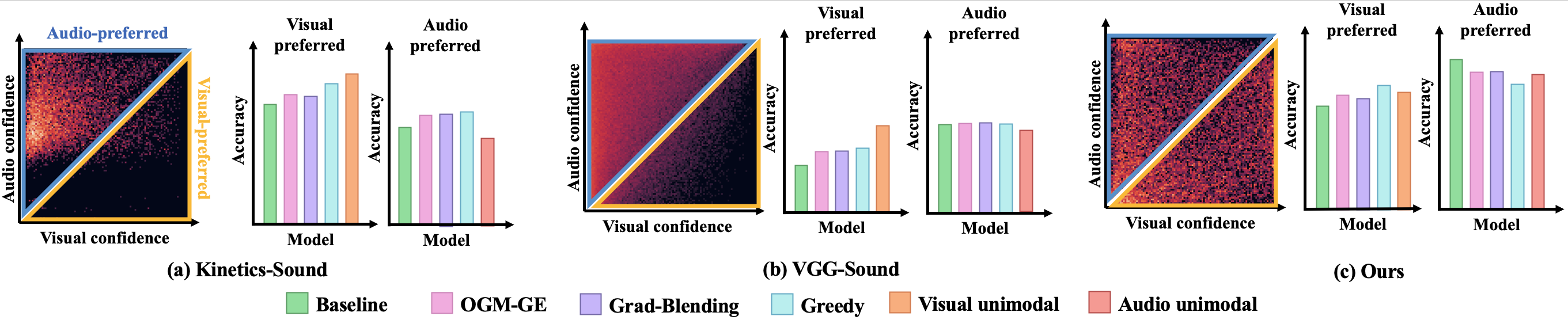
Figure 1: (a)-(b) show the heatmaps of modality discrepancy distribution and classification results on the existing datasets. The color represents the proportion of samples, the brighter area indicates larger samples. (c) shows our balanced heatmap and the classification results.
To provide a comprehensive analysis of this phenomenon, we first evaluate existing datasets into different subsets by estimating sample-wise modality discrepancy, and find that: although existing imbalance methods achieve better performance than unimodal modality on the overall testing set, they consistently perform worse than the unimodal model on the visual preferred testing subset across different datasets.
However, given the data-driven nature of deep learning, it is inevitable that the serious modality bias present in existing datasets. Thus, to further investigate the effectiveness of imbalance methods, we build a balanced audiovisual dataset containing samples with various modality discrepancies, and the allocation of such modality discrepancy remains uniformly distributed over the dataset.
Based on our balanced dataset, we re-evaluate existing imbalance methods and find that existing multimodal models would exhibit inferior performance than the unimodal one in scenarios with serious modality discrepancy. We highlight the importance of addressing this issue in future research to ensure the reliability of multimodal models across various application scenarios.
Dataset Statistic
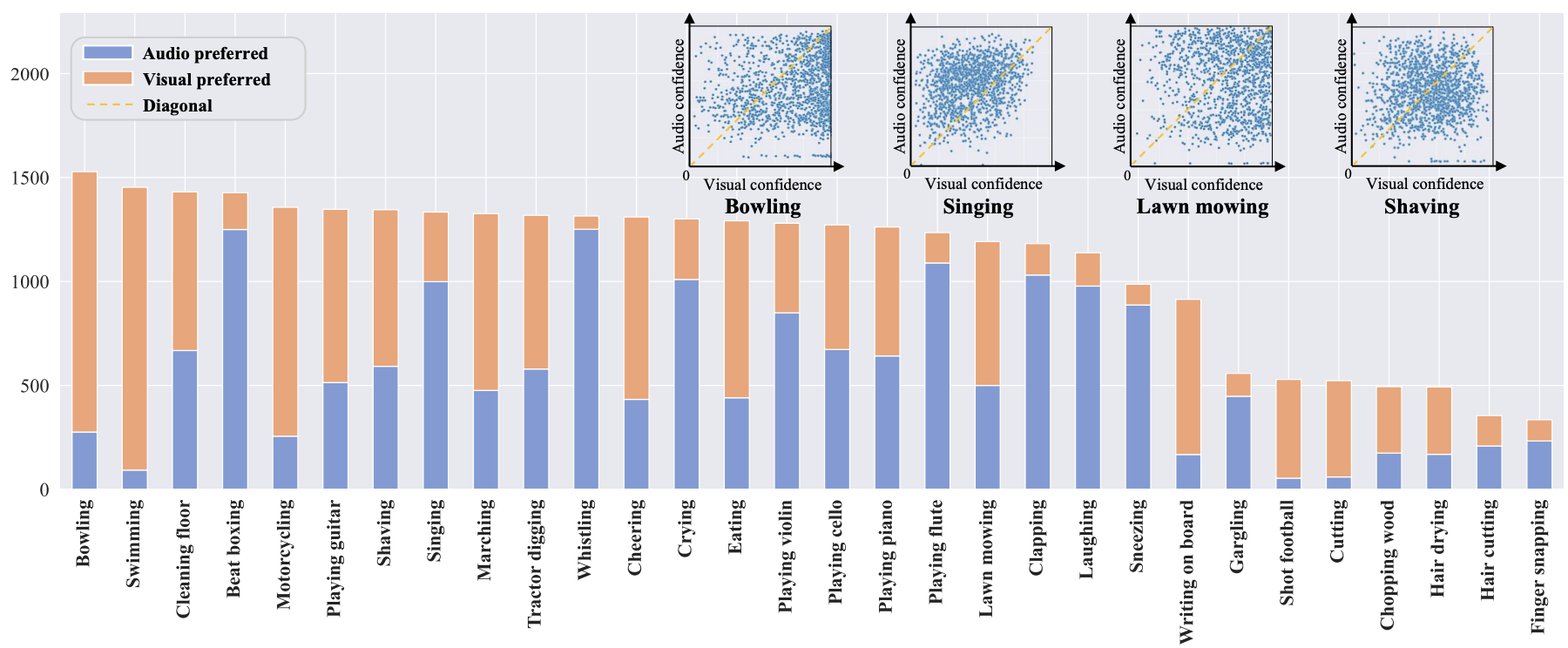
Figure 2: Illustrations of our balanced dataset statistics.
Our balanced audiovisual dataset obtains 35,851 videos for over 100 hours. We split our dataset into training, validation,and testing subsets with 28,949, 3,018, and 3,884 videos, respectively. We provide statistical analysis of our dataset in Figure 2. Although we have adopted filter methods to balance the modality discrepancy in each category, the intrinsic properties of categories make it hard to guarantee such balanced modality discrepancy. Even so, we still do our best to guarantee that each category has a relatively balanced modality discrepancy distribution, which makes our further analysis more reliable