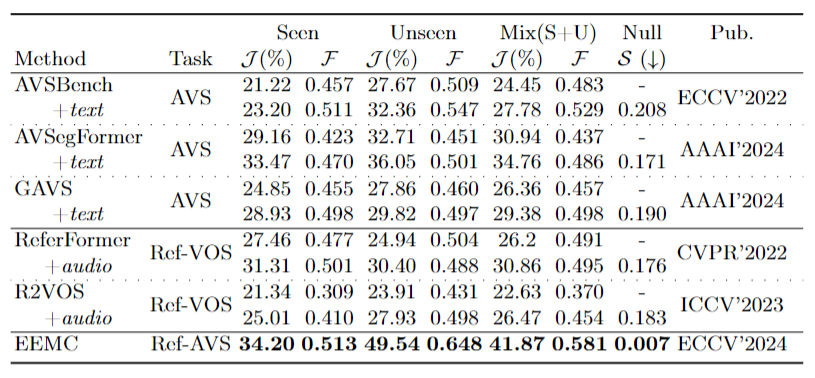
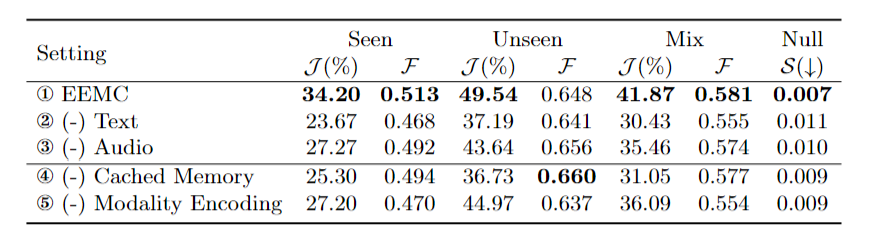
What is Ref-AVS task?
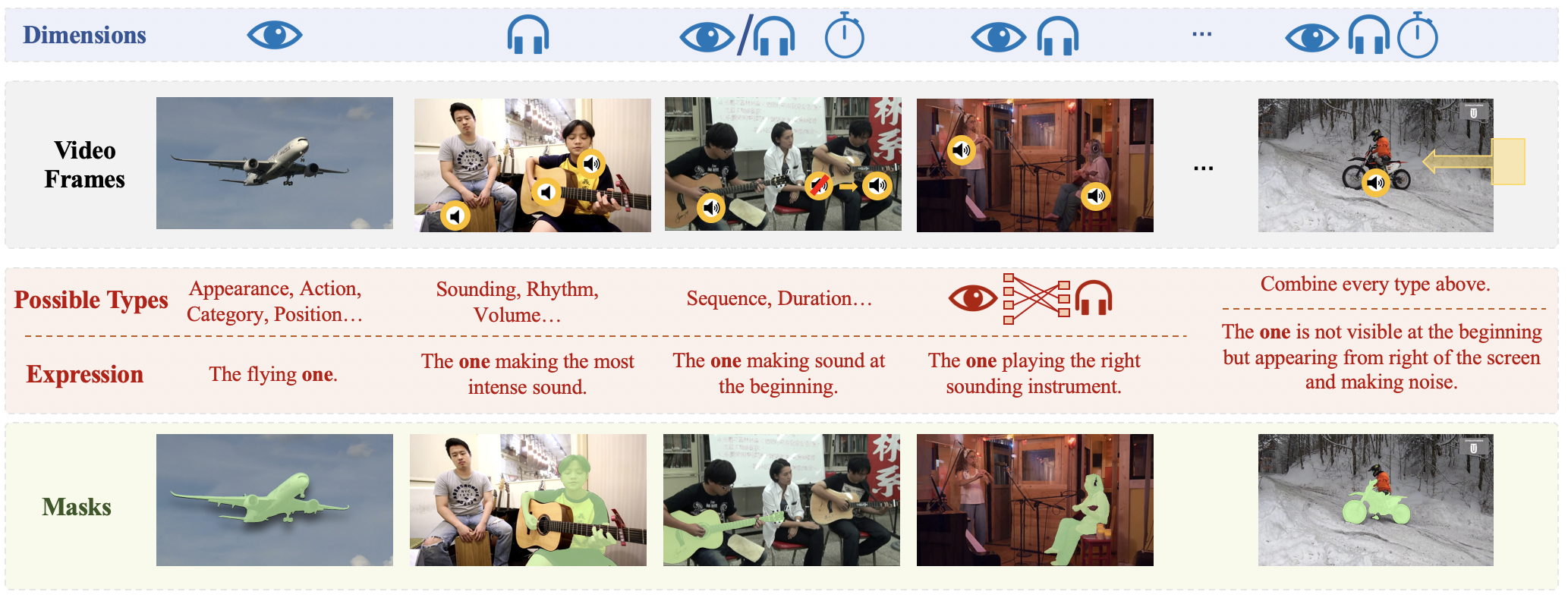
Traditional reference segmentation tasks have predominantly focused on silent visual scenes, neglecting the integral role of multimodal perception and interaction in human experiences. In this work, we introduce a novel task called Reference Audio-Visual Segmentation (Ref-AVS), which seeks to segment objects within the visual domain based on expressions containing multimodal cues. Such expressions are articulated in natural language forms but are enriched with multimodal cues, including audio and visual descriptions.
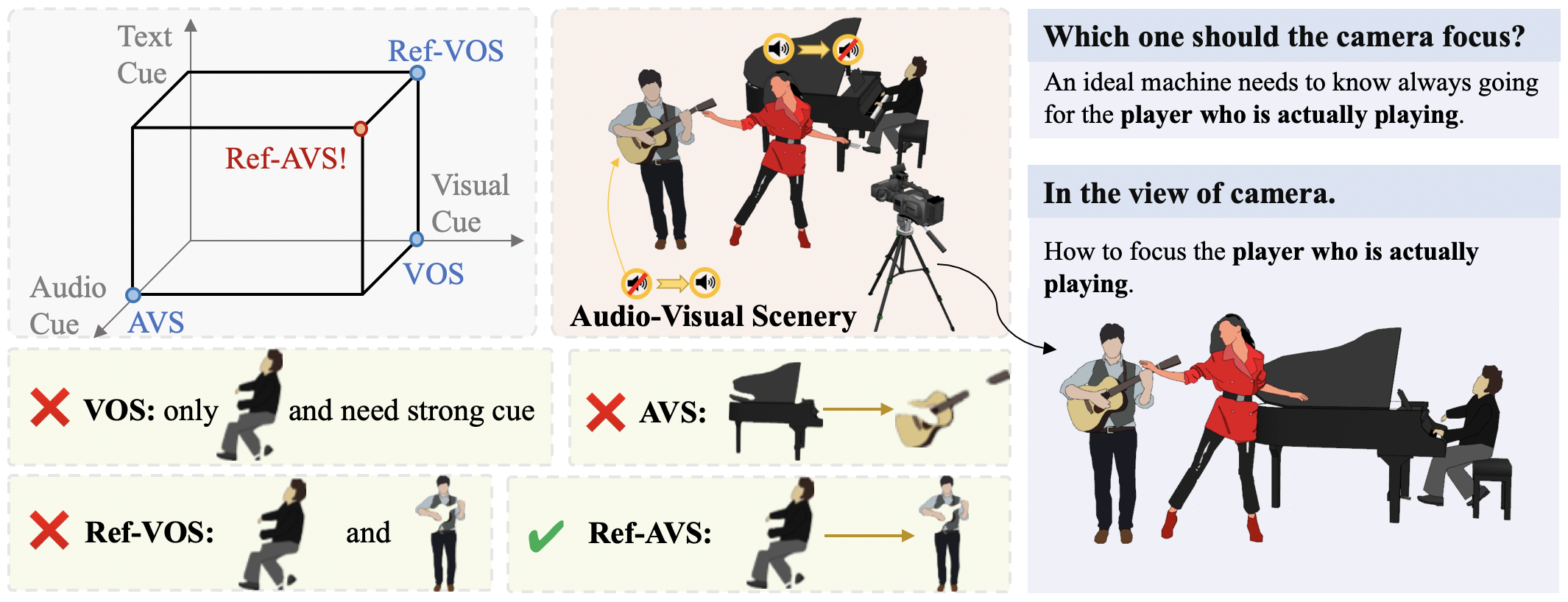
For instance, as shown in this Figure, Ref-AVS challenges machines to locate objects of interest in the visual space using multimodal cues, just like humans do in the real world, comparing to the Ref-AVS task with other related tasks..
What is Ref-AVS dataset?
To facilitate this research, we construct the first Ref-AVS benchmark, which provides pixel-level annotations for objects described in corresponding multimodal-cue expressions.
Basic informations
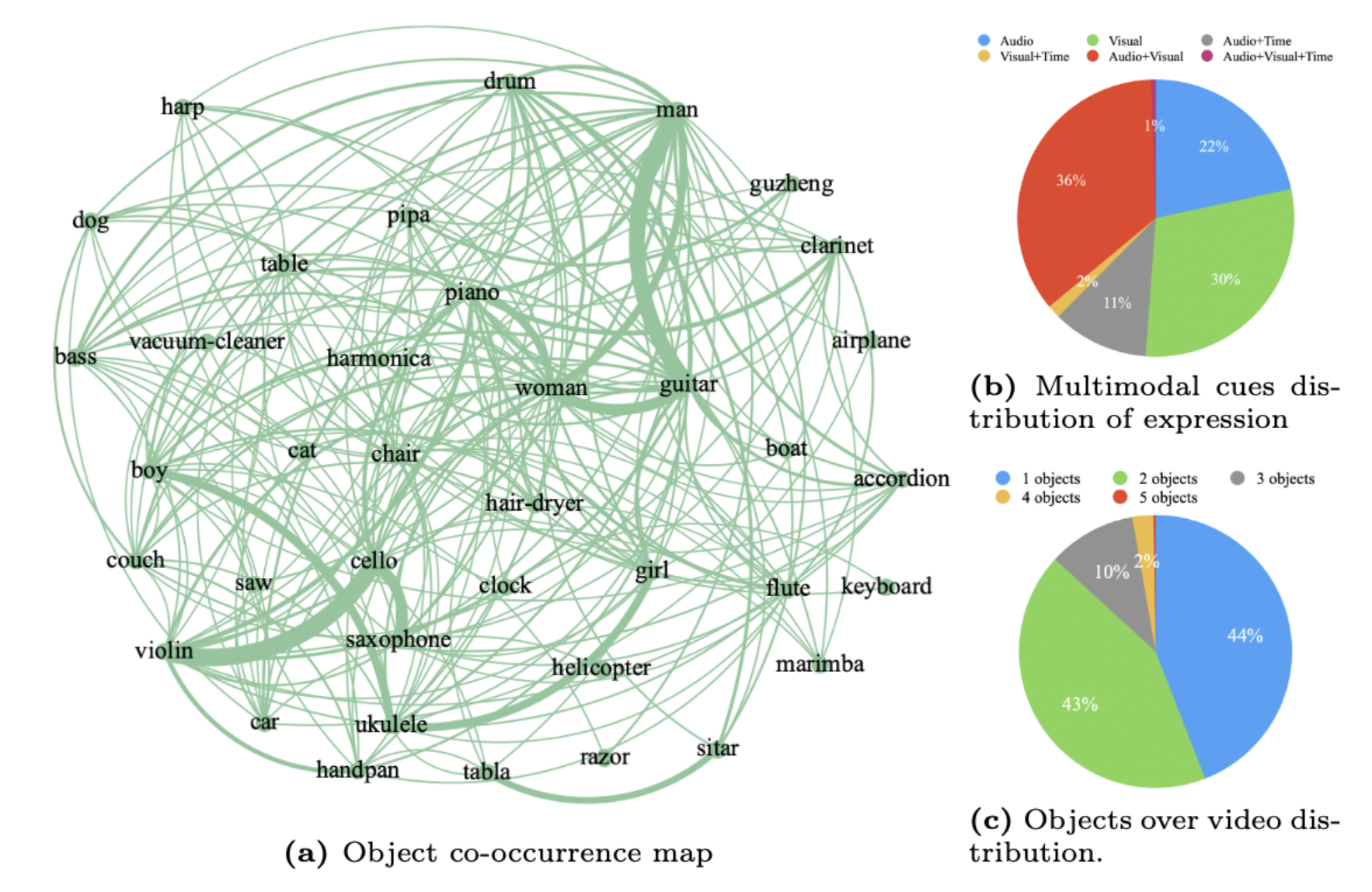
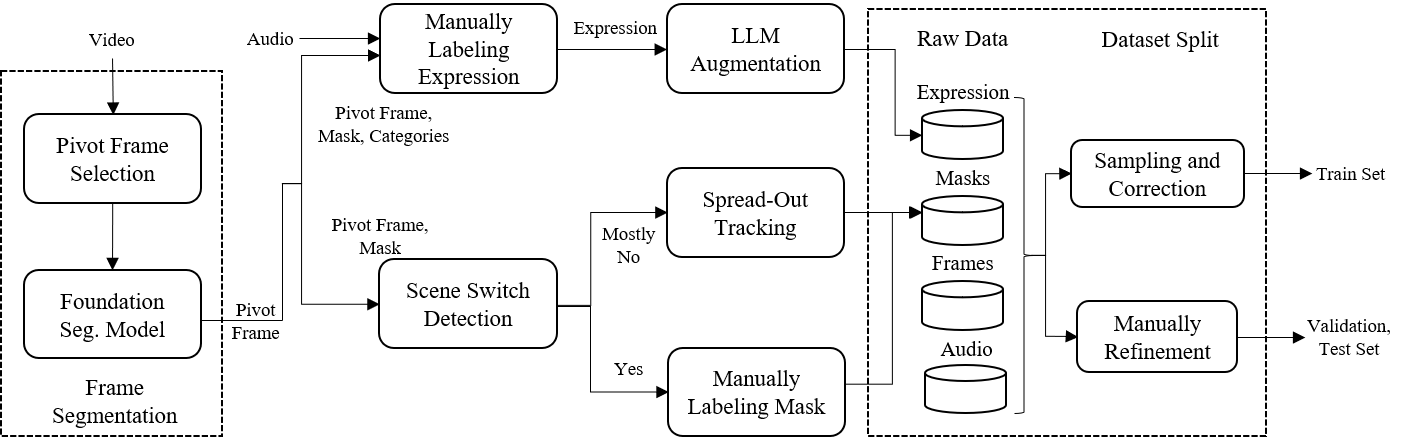
We choose to manually collect videos from YouTube. Specifically, 20 categories of musical instruments, 8 of animals, 15 of machines, and 5 of humans. Annotations are collected using our customized GSAI-Labeled system.
Characteristics
- 20,261 expressions
- 48 categories
- 4,002 videos
- 40,020 frames
- 6,888 objects
- Audio, visual, temporal
- Pixel-level annotation
- Diversity, complexity and dynamic
Personal data/Human subjects
Videos and Frames in Ref-AVS are public on YouTube, and annotated via crowdsourcing. We have explained how the data would be used to crowdworkers. Our dataset does not contain personally identifiable information or offensive content.