We live in a world filled with never-ending streams of multimodal information.
Videos captured from natural scenes have two typical characteristics:
1) Long form. They usually span several minutes, covering multiple related events in different categories. These events usually jointly contribute to depicting the main content of the video.
2) Audio-visual. Videos recorded in real-world scenarios usually comprise both audio and visual modalities. These two aspects often exhibit asynchrony, providing unique perspectives in delineating the video content, yet collaboratively facilitating video understanding.
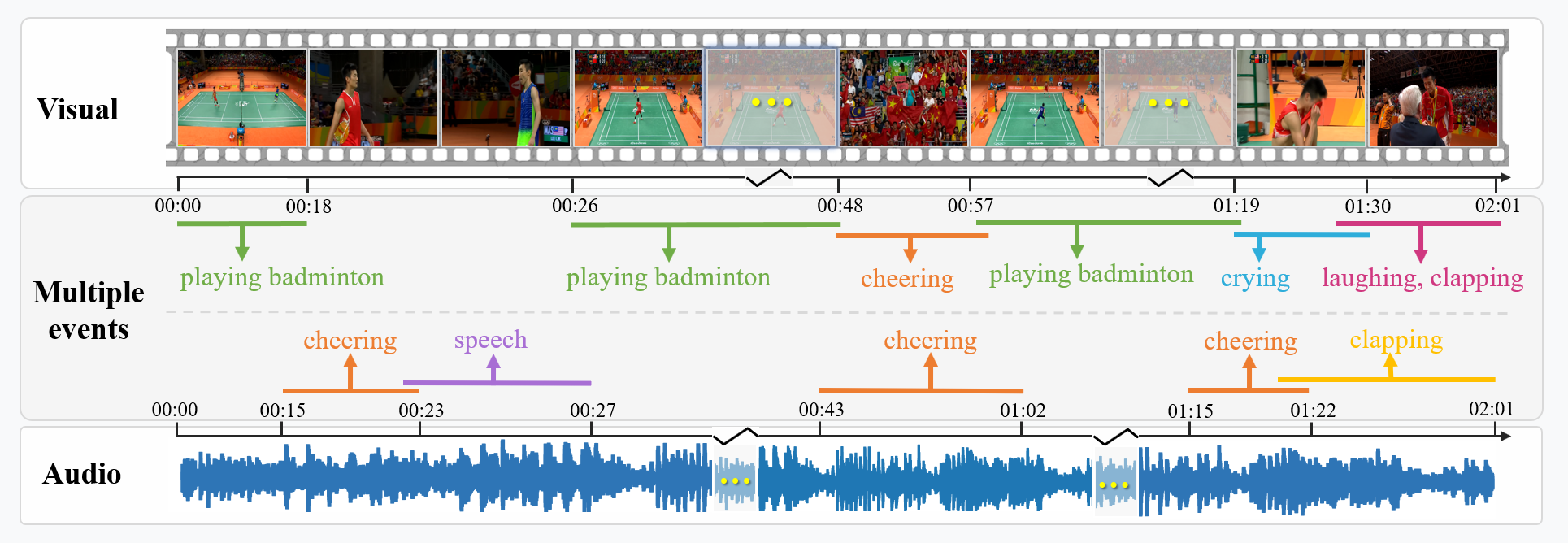
We show an example of long form audio-visual videos, with a length of 121-second.
This video shows a badminton game. The audio modality contains three events:
cheering, clapping and speech, the visual modality contains five events:
playing badminton, cheering, crying, laughing, and clapping.
The event cheering and clapping appears both in audio modality and visual modality.
These modality-aware events as well as their inherent relations help to effectively infer
what happens in the video then achieve a better understanding of the video content.
Considering the merits of the above two characteristics, we propose to study video understanding in terms of long form and audio-visual aspect,
name as long form audio-visual video understanding.
What is the multisensory temporal event localization task?
Task Definition. To achieve a better understanding of long form audio-visual videos, we propose to focus on the multisensory temporal event localization task,
which essentially requires the model to predict the start and end time of each audio and visual event in the video.
Concretely, we divide the video into several non-overlapping snippets, then predict the event categories of all snippets.
Challenges. Firstly, the video contains multiple events with diverse categories, modalities, and varying lengths.
Secondly, understanding the video content requires effectively modeling long-range dependencies and relations across different clips and modalities.
What is LFAV dataset?
To study the proposed multisensory temporal event localization task,
we elaborately build a large-scale Long Form Audio-visual Video (LFAV) dataset with 5,175 videos,
as existing datasets are not appropriate for our proposed task.
Information and highlights of the LFAV dataset are shown below.
Basic informations
We collect videos from YouTube, covering five kinds of daily life to ensure
the diversity, complexity, and dynamic of the real world:
human-related, sports, musical instruments, tools, and animals.
We also construct a label set of 35 kinds of events covering the above scenes,
Characteristics
5,175 videos
average length of 210 seconds and total length of 302 hours
average event categories of 3.15 per video.
Modality-aware annotations for all videos
Diversity, complexity and dynamic
Personal data/Human subjects
Videos in LFAV are public on YouTube, and annotated via crowdsourcing. We have explained how the data would be used to crowdworkers. Our dataset does not contain personally identifiable information or offensive content.
LFAV Dataset
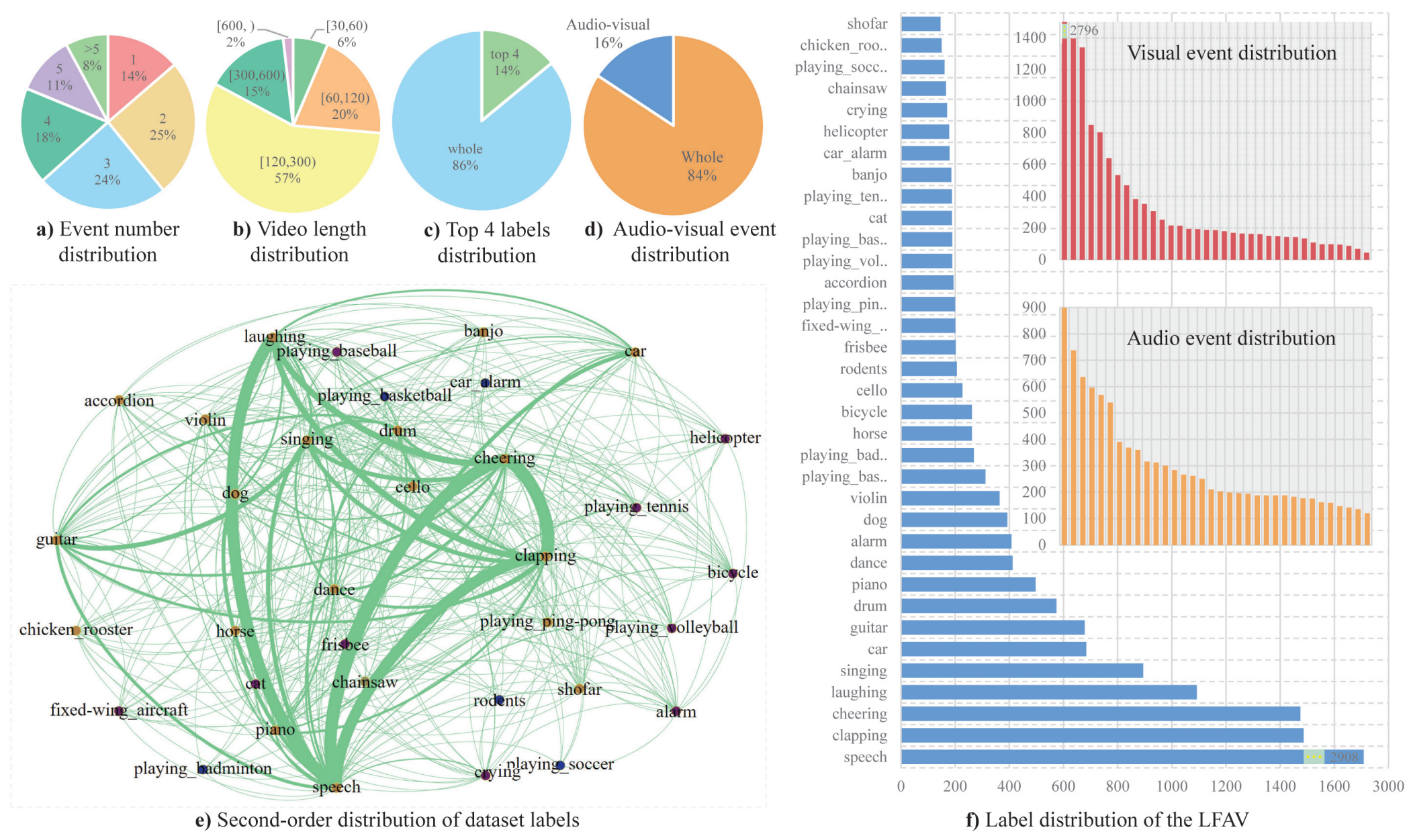
Illustrations of our LFAV dataset statistics
Dataset information
Illustrations of our LFAV dataset statistics.
(a-d) Statistical analysis of label categories, including the distribution of event numbers in each video;
the distribution of video length;
the proportion of the top 4 event categories,
the top 4 labels represent speech, clapping, cheering, and laughing, which are the most common human actions;
the temporal proportion of events that occur on two modalities at the same time.
(e) Second-order interactions between all labels, the thicker the line, the closer the association.
(f) Distribution of dataset labels black of each category.
Comparison with other datasets.
Our LFAV dataset is collected for the proposed multisensory temporal event localization task,
where diversified domains are covered.
Specifically, the LFAV dataset offers modality-aware annotations for each video,
that is it points out the events are from audio, visual, or both modalities.
Meanwhile, multiple events with different semantic categories are also annotated for better exploring the relation among events.
Videos in the dataset have an average length of 210 seconds and a total length of 302 hours.
† means the EPIC-KITCHENS-100 dataset contains two classification tasks, the label categories of them are 300 and 97, respectively.
‡ means the LVU dataset contains 7 classification tasks, the label categories of all 7 tasks are each no larger than 9.
* means the LLP dataset only provides modality-aware annotations invalidation and testing sets.
Video examples
Some video examples in the LFAV dataset. Each of them contains multiple modality aware events.
VGGish feature shape: [T, 128] , Download from
Google Drive or
Baidu Drive (pwd: lfav), (~662M)
ResNet18 feature shape: [T, 512] , Download from
Google Drive or
Baidu Drive (pwd: lfav), (~2.6G)
R(2+1)D feature shape: [T, 512] , Download from
Google Drive or
Baidu Drive (pwd: lfav), (~2.6G)
Annotations (train, val and test set): Available for download at GitHub.
We provide video-level annotations for the training set, provide both video-level and event-level annotations for validation and testing sets. The annotation files are stored in CSV format.
Training set
train_audio_weakly.csv: video-level audio annotaions of training set
train_visual_weakly.csv: video-level visual annotaions of training set
train_weakly.csv: video-level annotations (union of video-level audio annotations and visual annotations) of training set
Validation set
val_audio_weakly.csv: video-level audio annotaions of validation set
val_visual_weakly.csv: video-level visual annotaions of validation set
val_weakly_av.csv: video-level annotations (union of video-level audio annotations and visual annotations) of validation set
val_audio.csv: event-level audio annotaions of validation set
val_visual.csv: event-level visual annotaions of validation set
Testing set
test_audio_weakly.csv: video-level audio annotaions of testing set
test_visual_weakly.csv: video-level visual annotaions of testing set
test_weakly_av.csv: video-level annotations (union of video-level audio annotations and visual annotations) of testing set
test_audio.csv: event-level audio annotaions of testing set
test_visual.csv: event-level visual annotaions of testing set
Publication(s)
If you find our work useful in your research, please cite our paper.
@article{hou2023towards,
title={Towards Long Form Audio-visual Video Understanding},
author={Hou, Wenxuan and Li, Guangyao and Tian, Yapeng and Hu, Di},
journal={ACM Transactions on Multimedia Computing, Communications and Applications},
year={2023},
publisher={ACM New York, NY}
}
Disclaimer
The released LFAV dataset is curated, which perhaps owns potential correlation between instrument and geographical area. This issue warrants further research and consideration.
Copyright
All datasets and benchmarks on this page are copyright by us and published under the Creative Commons Attribution-NonCommercial 4.0 International License. This means that you must give appropriate credit, provide a link to the license, and indicate if changes were made. You may do so in any reasonable manner, but not in any way that suggests the licensor endorses you or your use. You may not use the material for commercial purposes.
An event-centric framework
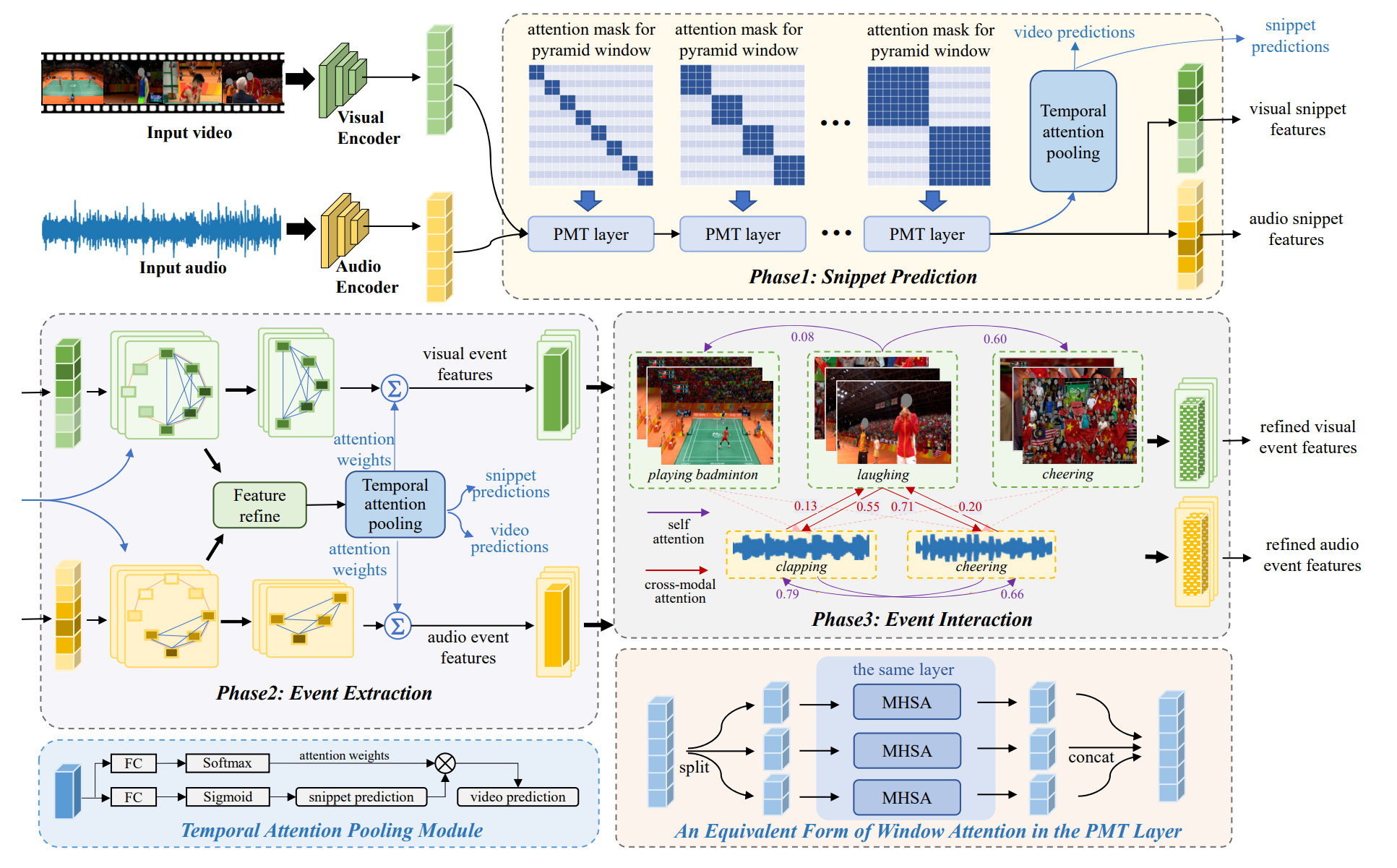
We propose an event-centric framework that contains three phases from snippet prediction, event extraction to event interaction.
Firstly, we propose a pyramid multimodal transformer model to capture the events with different temporal lengths,
where the audio and visual snippet features are required to interact with each other within multi-scale temporal windows.
Secondly, we propose to model the video as structured event graphs according to the snippet prediction,
based on which we refine the event-aware snippet-level features and aggregate them into event features.
At last, we study event relations by modeling the influence among multiple aggregated audio and visual events and then refining the event features.
The three phases progressively achieve a comprehensive understanding of video content as well as event relations
and are jointly optimized with video-level event labels in an end-to-end fashion.
We want to highlight that the inherent relations among multiple events are essential for
understanding the temporal structures and dynamic semantic of the long form audio-visual videos,
which has not been sufficiently considered in previous event localization works.
More details are in the paper (paper).
An illustration of our event-centric framework. Top: In the first phase of snippet prediction, we propose a pyramid
multimodal transformer to generate the snippet features as well as their category prediction. Middle left:
In the second phase of event extraction, we build an event-aware graph to refine the snippet features and
then aggregate the event-aware snippet features into event features. Middle right: In the third phase of
event interaction, we model the event relations in both intra-modal and cross-modal scenarios and then
refine the event feature by referring to its relation to other events. Bottom left The architecture of temporal
attention pooling. It both outputs snippet-level predictions and video-level predictions. The inside attention
weights are used to obtain event features in the event extraction phase. Bottom right: An equivalent form of
window attention in the PMT Layer, shows how the window operates in the first phase. The window splits the
feature sequence into several sub-sequences, then these sub-sequences are performed attention operations
respectively. Here we show an example of self attention, operation in cross-modal attention is similar.
Experiments and Analysis
Main experiment results
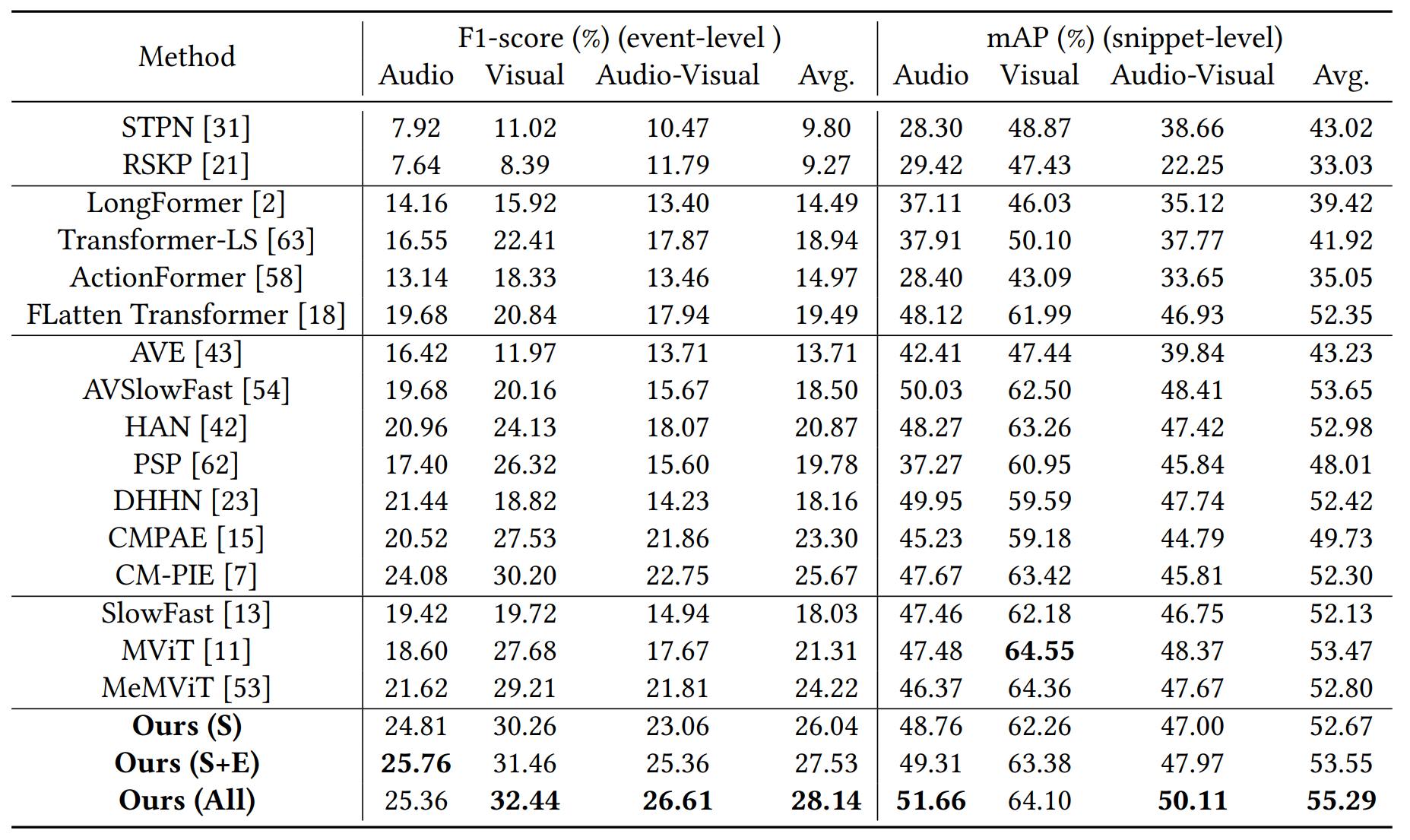
To validate the superiority of our proposed framework, we choose 16 related methods for comparison,
including weakly supervised temporal action localization methods: STPN, RSKP;
long sequence modeling methods: Longformer, Transformer-LS, ActionFormer, FLatten Transformer;
audio-visual learning methods: AVE, AVSlowFast, HAN, PSP, DHHN, CMPAE, CM-PIE;
video classification methods: SlowFast, MViT, and MeMViT.
Comparison to Other Methods.Firstly, temporal action localization and long sequence modeling methods
aim to effectively localize action events in untrimmed videos or model long sequences.
But they ignore the valuable cooperation among audio and video modality, which is important in achieving more comprehensive video event understanding.
Secondly, although some methods take the audio signal into account, they are consistently worse than our method.
This could be because they mainly aim at understanding trimmed short videos, resulting in limited modeling of long-range dependencies and event interactions.
Thirdly, our proposed method outperforms all the comparison ones obviously, although some recent video classification methods
achieve slightly better results on visual mAP, their overall performance still lags obviously behind our proposed method,
showing that our proposed event-centric framework can localize both audio and visual events in long form audio-visual videos better.
Effectiveness of Three Phases. Our full method consists of three progressive phases.
The performance of the snippet prediction phase has already surpassed most comparison methods,
then the subsequent phases can further improve localization performance.
Results are shown in the last three rows of the above Table,
which indicate the potential importance of decoupling a long form audio-visual video into multiple uni-modal events with different lengths and modeling their inherent relations in both uni-modal and cross-modal scenarios.
Visualization results
We visualize the event-level localization results in the videos, two examples are shown in the above figure. Compared with the audio-visual video parsing method HAN,
our proposed method achieves better localization results.
In some situations (e.g., event guitar in both audio and visual modality of video 01, and event speech in the audio modality of video 02),
HAN tends to localize some sparse and short video clips instead of a long and complete event, which shows that HAN exists some limitations to understanding long-form videos.
The possible reason is that HAN cannot learn long-range dependencies well.
We also notice that, although our proposed event-centric method has achieved the best performance among all methods,
there still exist some failure cases in the shown examples (red and black boxes in the figure).
The multisensory events take huge different lengths and occur in a dynamic long-range scene,
which makes multisensory temporal event localization become a very challenging task,
especially with only video-level labels in training. More experiment results and analysis are in the paper (paper).