Abstract
Online Imitation Learning struggles with the gap between extensive online exploration space and limited expert trajectories, hindering efficient exploration due to inaccurate reward estimation. Inspired by the findings from cognitive neuroscience, we hypothesize that an agent could estimate precise task-aware reward for efficient online exploration, through decomposing the target task into the objectives of "what to do" and the mechanisms of "how to do". In this work, we introduce the hybrid Key-state guided Online Imitation (KOI) learning method, which leverages the integration of semantic and motion key states as guidance for reward estimation. Initially, we utilize visual-language models to extract semantic key states from expert trajectory, indicating the objectives of "what to do". Within the intervals between semantic key states, optical flow is employed to capture motion key states to understand the mechanisms of "how to do". By integrating a thorough grasp of hybrid key states, we refine the trajectory-matching reward computation, accelerating online imitation learning by task-aware exploration. We evaluate not only the success rate of the tasks in the Meta-World and LIBERO environments, but also the trend of variance during online imitation learning, proving that our method is more sample efficient. We also conduct real-world robotic manipulation experiments to validate the efficacy of our method, demonstrating the practical applicability of our KOI method.
Introduction
Online Imitation Learning has achieved significant success in various robotic manipulation tasks, driven by a reward function informed by expert demonstrations, is able to formulate policies via exploration. However, the considerable gap between substantial online exploration space and limited expert trajectories challenges the estimation of exploration reward, which hinders the efficiency of online imitation learning in intricate environments.
Inspired by the findings from cognitive neuroscience, we propose the hybrid Key-state guided Online Imitation (KOI) learning method, which effectively extracts the semantic and motion key states from expert trajectory to refine the reward estimation.
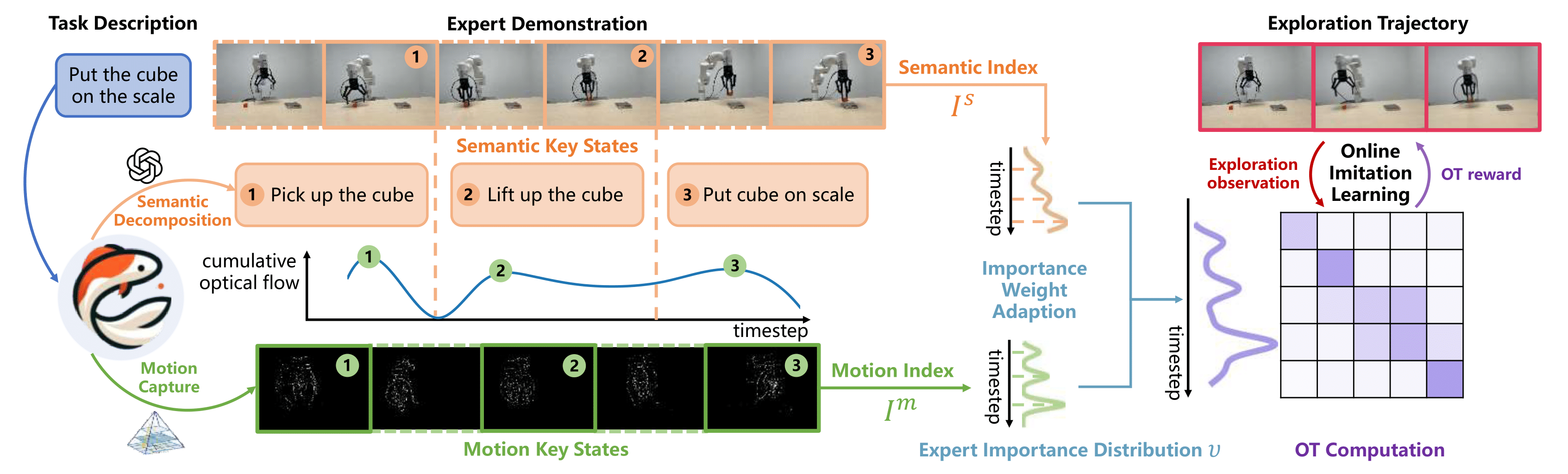
Figure 1: The pipeline of our hybrid Key-state guided Online Imitation (KOI) learning method.
As demonstrated in Figure 1, we initially utilize the rich world knowledge of visual-language models to extract semantic key states from expert trajectory, clarifying the objectives of "what to do". Within intervals between semantic key states, optical flow is employed to identify essential motion key states to comprehend the dynamic transition to the subsequent semantic key state, indicating "how to do" the target task. By integrating both types of key states, we adjust the importance weight of expert trajectory states in OT-based reward estimation to empower efficient online imitation learning.
Experiments
Simulation
To comprehensively evaluate our key-state guided method, we conducted experiments across 6 manipulation tasks from the Meta-world and 3 more complex tasks from the LIBERO. In offline imitation phase, we collected 1 demonstration and 50 demonstrations per task in the Meta-world and LIBERO to train a Behavior Cloning (BC) policy, respectively. For online imitation phase, we loaded pretrained BC policy and initialized critic network.
We compare our method with other methods:
1. BC, which represents the pretrained behavior cloning policy.
2. UVD, which utilize pretrained visual encoder R3M for task decomposition in image-goal reinforcement learning.
3. RoboCLIP, which leverages the pretrained video encoder S3D to estimate the task-aware reward function instead of the reward of each state.
4. ROT, which employs Optimal Transport to estimate the distance between exploration trajectory and expert demonstrations, which focus on fine-grained trajectory matching.
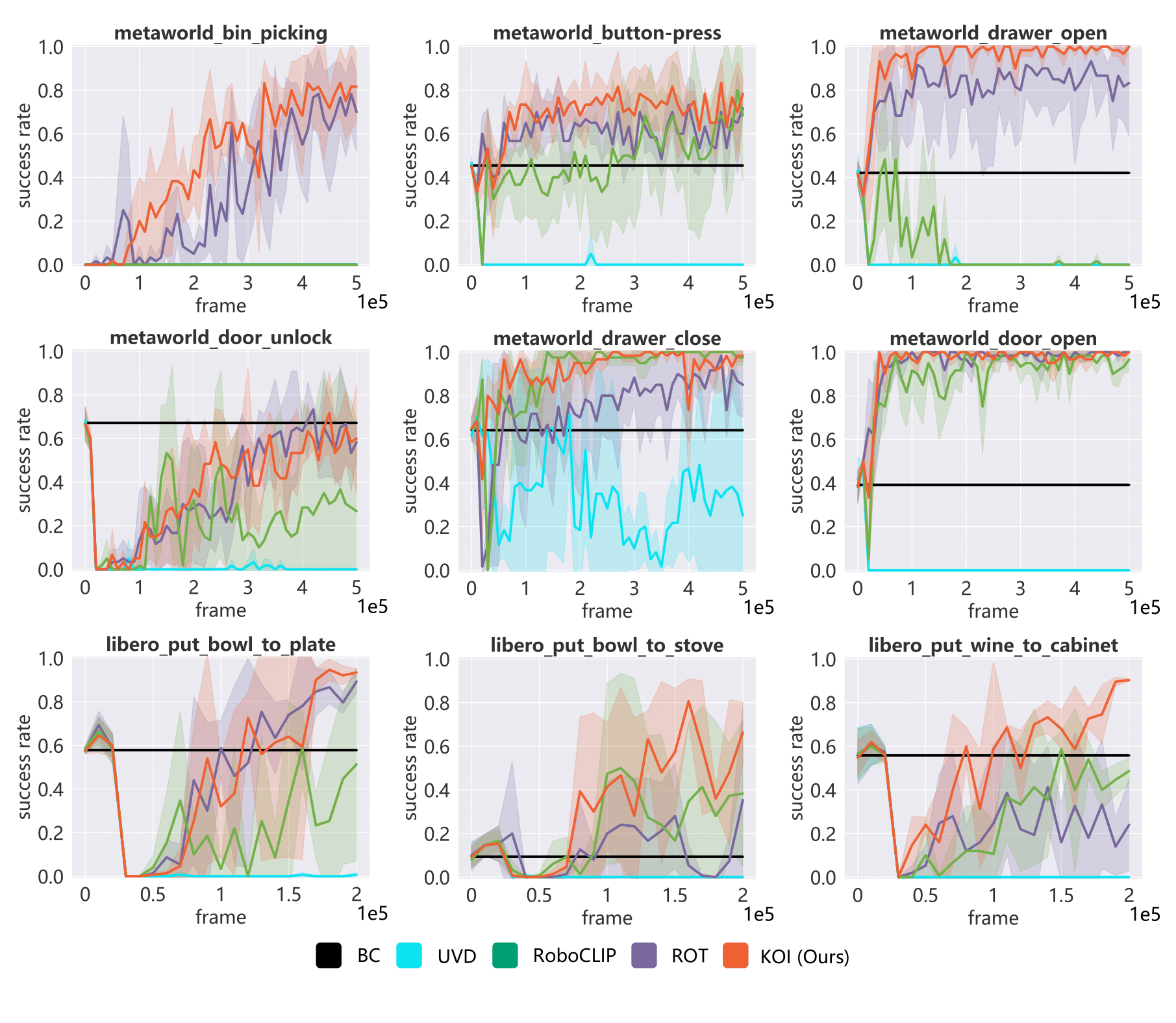
Figure 2: The experiment results on Meta-World and LIBERO, with exploration 5 x 1e5 and 2 x 1e5 timesteps respectively. The shaded region represents normalized standard deviation across 3 seeds.
As shown in Figure 2, our KOI method achieves more efficient online imitation learning in all tasks by leveraging a thorough comprehension of both semantic and motion key states, providing a distinct advantage. Furthermore, KOI not only yields more efficient learning but also maintains greater stability, benefiting from the comprehensive guidance from the hybrid key states.
Real-world
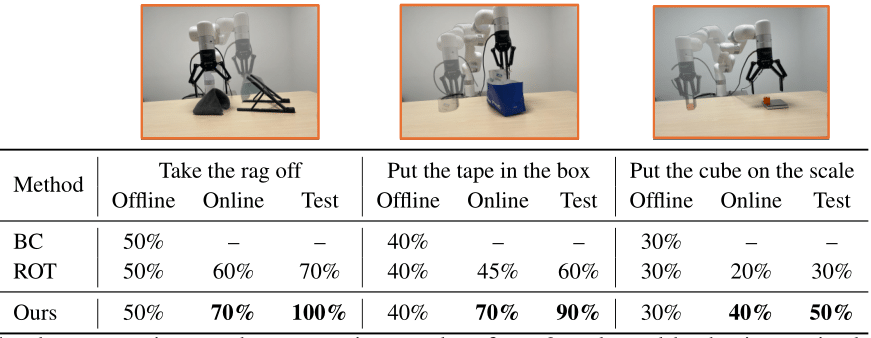
Table 1: The demonstrations and comparative results of our 3 real-world robotic manipulation tasks. The initial state of each task is represented in a lighter shade, while the completed state is depicted in a darker shade. The results indicate that our method achieves more efficient exploration and better overall performance.
As shown in Table 1, We conduct real-world experiments using an XARM robot equipped with a Robotiq gripper. To comprehensively evaluate the performance, the entire imitation learning is divided into three stages: offline, online, and test. For each task, we collect 10 human expert demonstrations to train the Behavior Cloning (BC) policy during the offline phase and use only 1 expert demonstration to estimate reward during the online phase. All the evaluations are conducted at varying initial object positions. Our method utilizes task-aware information to improve the reward estimation, thereby enhancing the agent's exploration efficiency and performance.
Conclusion
In this work, we propose the hybrid Key-state guided Online Imitation (KOI) learning method, which extracts the semantic and motion key states for trajectory-matching reward estimation for online imitation learning. By decomposing the target task into the objectives of "what to do" and the mechanisms of "how to do", we refine the trajectory-matching reward estimation to encourage task-aware exploration for efficient online imitation learning. The results from simulation environments and real-world scenarios prove the efficiency of our method.